摘要:
基于region proposal算法的目标检测工作,比如SPPnet和Fast RCNN等已经减少了检测网络的运行时间,但是region proposal计算仍然很耗时。本文引入了RPN可以共享整幅图的卷积特征,使得检测工作的region proposal几乎不耗时。
RPN网络时一个全卷积网络,能够同时预测目标边界和分数。RPN是端到端训练的产生高质量的region proposal,我们通过卷积参数共享,将RPN和Fast RCNN融合进一个网络[attention机制]。
引言
基于region的检测器的卷积特征图,比如Fast RCNN使用的,也可以用来产生region proposal。在这些卷积特征之后,我们构建了RPN网络同时回归region 边界和目标分数。RPN可以预测大范围尺度和纵横比的region proposal。和之前使用图像金字塔或者滤波器金字塔不同,我们引入了anchor。
如图c,不需要列举多种尺度和纵横比的图片和滤波器,这是一种回归参考金字塔。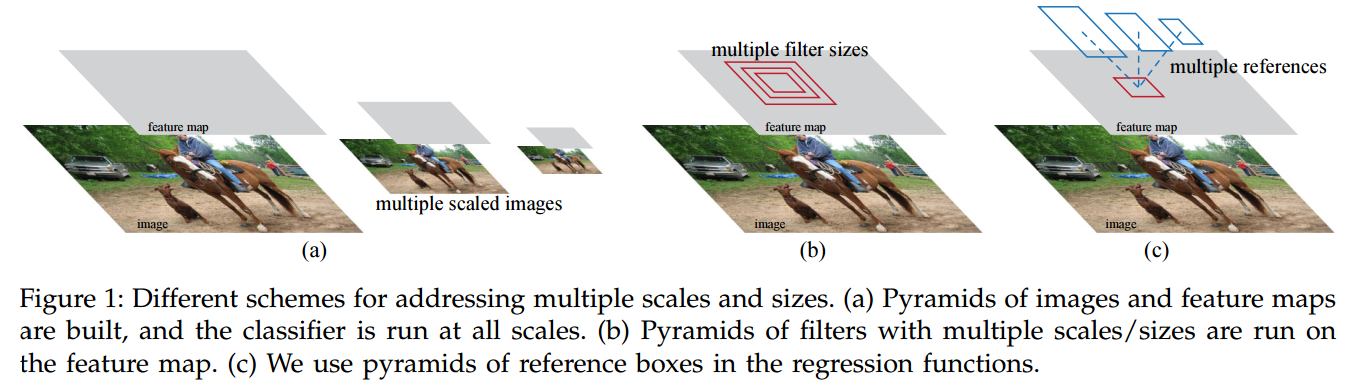
为了将RPN统一到Fast RCNN中,提出了一种训练策略,交替fine-tune region proposal和object detection。这个策略收敛很快,并且能够产生在两个任务间共享的卷积特征。
相关工作
object proposal
广泛使用的object proposal方法包括:超像素聚类(selective search),和滑动窗(EdgeBox)。总之,object proposal的提取方法都是作为外部模块和检测器相独立的。
Deep Networks for Object Detection
RCNN主要是作为分类器,没有预测目标边界,除了精修bounding box回归外。他的精确度依赖于region proposal模块的性能。
Overfeat方法训练了一个全连接层来预测box的坐标。
MultiBox方法
Faster RCNN
本网络有两个模块组成。第一个模块是深度全卷积网络用来产生region proposal,第二个模块使用region proposal来做检测。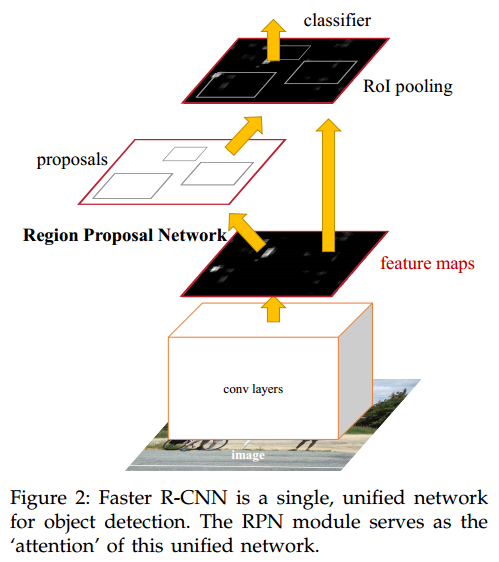
整个系统是一个统一的网络,通过attention机制,RPN模块告诉Fast RCNN模块应该在寻找。
Region Proposal Networks
RPN可以输入任意大小的图片,并输出一组矩形的object proposal,每个都有属于目标的分数。我们用一个全卷积网络建模,因为最终目标是和Fast RCNN目标检测网络共享计算,所以假设两个网络共享一组卷积层。在实验中,使用了ZF网络和VGG16网络,分别有5个共享的卷积层和13个共享的卷积层。
为了产生region proposal,用一个小的网络在最后一层卷积图产生的特征图上滑动。每个滑动窗被映射到一个低维特征(ZF 256-d,VGG16 512-d)。这个特征被喂入两个并列的全卷积层中,一个box回归层和一个box分类层。有效的感受野很大,分别是ZF 171像素,VGG16是228像素。这个mini网络如图3所示。因为该网络是按滑动窗方式工作,因此全连接层在所有空间位置被共享。整个框架是由n*n的卷积层加两个1*1的卷积层构成的。
Anchors
在每个滑动窗处,同时预测多个region proposal。每个位置处可能的proposal数量记为$k$.因此reg层与$4k$个输出,表示$k$个box的坐标。cls层输出$2k$的分数表示每个proposal是目标和不是目标的概率。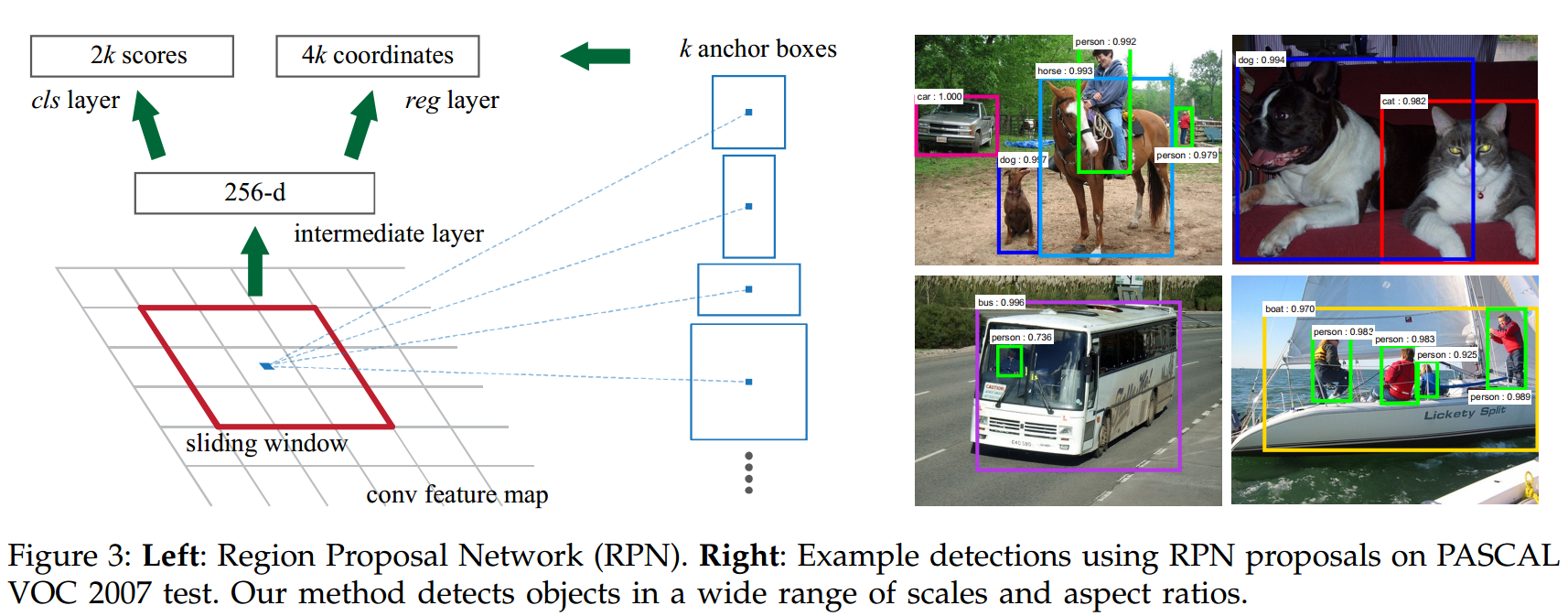
anchor 在滑动窗口的中心,默认使用3种尺度和3种纵横比,即对一个卷积特征图$WH$来说,有$WHk$个anchor。
translation-invariant anchors
如果图片中的anchor目标平移了,那么proposal也会平移,并且之前的函数仍能预测该proposal,这就是平移不变性。这种特性也减小了模型的大小。MultiBox有$(4+1)\times800$维全连接输出,而我们的方法只有$(4+2)\times9$维的卷积输出。输出层只有$2.8\times10^4$参数($512\times(4+2)\times9$ for VGG16)。即便考虑特征映射层,我们的proposal层的参数也比MultiBox少两个阶数,因为我们希望我们的方法在类似PASCAL VOC这样的小数据集上不会过拟合。
Multi-Scale Anchors as Regression References
图1中,有两种解决多尺度预测的方法。
第一种是基于图像/特征金字塔,比如在DPM和CNN的方法中。图像被resize到不同尺度,每个尺度都计算一遍特征图。这种方法有效但耗时。
第二种是在特征图上使用不同尺度(或纵横比)的滑动窗口。比如,DPM中,会使用不同尺寸的滤波器分别训练不同纵横比的模型(如图1b)。
基于anchor的方法建立了一种anchor金字塔,依据不同尺度和纵横比的anchor来分类和回归boundingbox。他只依赖于一种尺度的图像或者特征图,滤波器的尺寸也是一种。这种多尺度的anchor是共享卷积特征的关键。
损失函数
训练RPN时,为每个anchor分配一个是目标或不是目标的标签。正样本,和groundtruth有最高IOU重叠的anchor;或者和groundtruth的IOU重叠大于0.7的anchor。注意一个groundtruth可以给anchor分配多个正样本的标签。负样本:IOU比例小于0.3。那些既不是正样本也不是负样本的anchor对训练目标函数没有贡献。
我们根据Fast RCNN中的多任务损失来最小化目标函数。我们的损失函数定义如下:
$$L({p_i},{t_i})=\frac{1}{N_{cls}}\sum_iL_{cls}(p_i,p_i^) + \lambda\frac{1}{N_{reg}}\sum_ip_i^*L_{reg}(t_i,t_i^).\qquad (1)$$
$i$是一个mini batch找那个一个anchor的索引,$p_i$是预测anchor $i$是否为目标的概率。如果anchor是正样本那么$p_i^*$为1,否则为0。$t_i$是代表了预测的bounding box的四个参数化坐标,$t_i^*$是正样本anchor的ground truth的坐标。
分类损失$L_{cls}$是二类对数损失,回归损失$L_{reg}(t_i,t_i^*)=R(t_i-t_i^*)$,其中$R$是(smooth L1)损失。$p_i^*L_{reg}$表示回归损失只对正anchor有效($p_i^*=0$)。分类层和回归层分别输出${p_i}$和${p_i^*}$。
上式两项分别有$N_{cls}$和$N_{reg}$进行归一化,并且由$\lambda$平衡权重。现在实现中,$N_{cls}=256$,即mini-batch大小;$N_{reg}\approx2400$即为anchor的数量。默认将$\lambda=10$,这样分类和回归损失可以大约平衡了。实验证明,结果对$\lambda$很不敏感,取值范围很宽。另外,以上的归一化也不需要可以省略。
对于bounding box回归,我们采取以下参数化的方法:
$$
\begin{split}
& t_x=(x-x_a)/w_a,t_y=(y-y_a)/h_a,\
& t_w=log(w/w_a),t_h=log(h/h_a),\
& t_x^=(x^-x_a)/w_a,t_y^=(y^-y_a)/h_a,\
& t_w^=log(w^/w_a),t_h^=log(h^/h_a),
\end{split}\tag{2}
$$
其中,$x,y,w,h$表示box的中心坐标和宽高。变量$x,x_a,x^*$分别是预测出框,anchor,和groundtruth box。这个bounding box回归过程可以被认为是从一个anchor回归到临近的ground truthbox的过程。
bounding box回归是根据任意大小的RoIs上池化得到的特征进行的,并且回归的权值被所有的region所共享。在我们建模中,回归过程所用的特征都是一样大的(3*3)。
为了适应变化的ROI大小,学习了k个bounding box回归器。每个回归器负责一种尺寸和纵横比,并且这k个回归器不共享权值。即便特征是一个固定尺度,我们仍能够预测不同大小的box。
训练RPN
RPN训练时可根据SGD和后向传播来端到端训练,每个mini-batch是从一张图中的anchor组成。随机采样256个anchor并且保证正负样本比率为1:1.如果有少于128个正样本,就用负样本填充mini-batch。
开始使用一个均值为0、标准差0.01的高斯分布来初始化所有的RPN层。其他的共享卷积层则是由ImageNet分类上的预训练模型初始化的,tune VGG16中conv3_1及以上的所有层。
Sharing Features for RPN and Fast R-CNN
我们需要在学习过程中共享RPN和Fast RCNN的参数,而不是分别学习两个网络。有两种方案:
- 交替学习:先训练RPN,然后使用proposal来训练Fast RCNN.由Fast RCNN tune的网络再用来初始化RPN网络,依次迭代。本文所有实验采用这种方法。
- 近似联合训练:每次SGD迭代中,前向传播产生近似固定大小的,预计算的region proposal,后向传播过程中,共享层的RPNloss和Fast RCNNloss一起传递梯度。这种方法省了1/4的时间。
实现细节
无论测试还是训练,图片都是一个尺寸,将图片resize到短边$s=600$像素。多尺度的特征提取器(使用图像金字塔)可能提高精度但是速度就很慢。我们recsale之后的图片,对于ZF还是VGG的最后一层卷积层来说,总的步长都是16像素。如果步长更小,结果可能会更好。
对于anchor,我们使用了3种尺度。box大小分别是$128^2$,$256^2$,$512^2$像素,3种横纵比:$1:1$,$1:2$,$2:1$。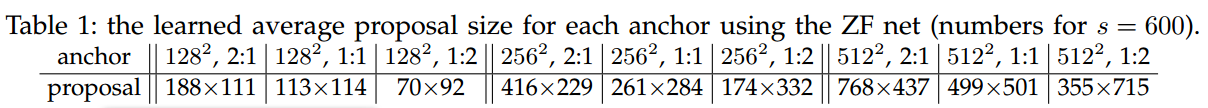
上表表示使用ZF网络学习到的每种anchor的平均proposal size。
超过图片边界的proposal需要小心处理。训练时忽略了所有这种anchor。对于一张1000*600的图片,大约有20000个anchor,忽略掉穿出图像边界的anchor,还剩6000个每幅图。
一些RPN的proposal会相互重叠,我们根据cls分数使用NMS来去除冗余的proposal。NMS的阈值为0.7,剔除后每张图还剩2000个proposal了。NMS不会影响精确性,并且能够减少proposal的数目。抑制之后,在使用前N个proposal来检测。