摘要:
该文章有两个主要关键见解:1.使用CNN来自底向上产生region proposals来定位和分割目标。2. 当标记的训练样本不足时,有监督的预训练来进行辅助任务,接着fine-tuning,可以产生显著的性能提升。将regions和CNN结合的方法叫做RCNN,在VOC2012的数据集上达到了mAP53.3%的成绩。同时,作者也将该方法与OverFeat在200类目标的ILSVRC2013的数据集上进行对比。
引言
使用CNN进行目标检测有两个挑战:
- 利用滑动窗口进行目标检测时,对于5层的卷积层会有非常大的感受野(195*108)。对于精确定位不利。
- 训练CNN的样本不足。
我们采取的解决方法是利用无监督的预训练加上有监督的fine-tuning。在一个大的辅助数据集(ILSVRC)上进行有监督的预训练,然后再在一个小的数据集(PASCAL VOC)上进行特定的fine-tuning。
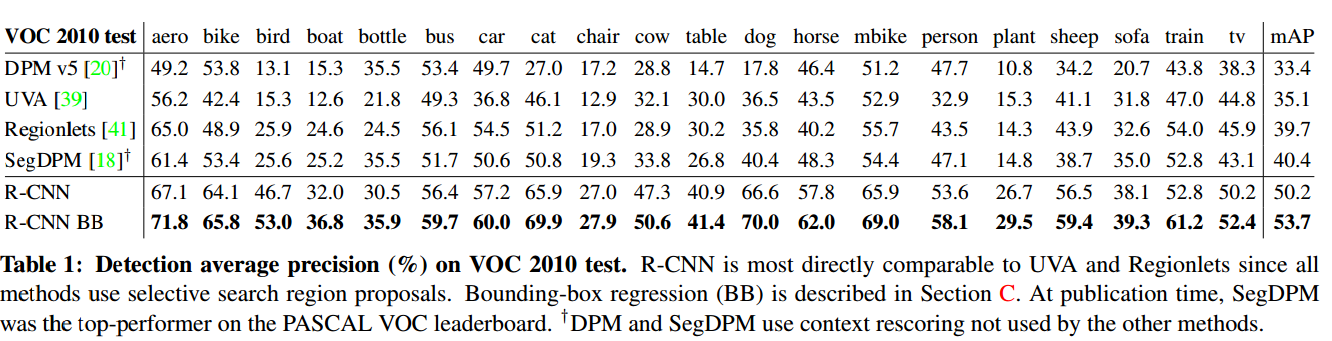
test 过程:首先输入一张图片;提取大约2000个(category-independent)自底向上的region proposals;然后使用一个大的CNN网络来计算每个proposal的特征;最后使用特定类(class specific)的线性SVM进行分类。RCNN在PASCAL VOC2010上的mAP达到了53.7%。
我们用一个简单的技巧(affine image warping)从每个region proposal来计算出一个固定大小的CNN输入。
Objection detection with R-CNN
我们的目标检测系统包含三个模块:首先产生类别独立的region proposal,这些proposal定义了能够输入检测器的候选检测集合。第二个模块是个大的卷及审计网络,从每个region提取出固定长度的特征向量。第三个模块是一组特定类别的线性SVM。
Module design
Region proposals
很多方法是要产生category-independent的region proposals。虽然RCNN对于特定的region proposal方法是不可知的,因此我们使用selective search 以方便和之前的检测工作进行对比。
Feature extraction
将一幅减去均值的RGB图像(227*227)作为输入,紧跟着5层卷积层和2层全连接层。通过前向传播计算特征,从每个region proposal提取一个4096维的特征向量。
为了计算一个region proposal的特征,我们首先要把这个region队形的图像数据转换成能够和CNN兼容的兴衰(CNN需要固定输入227*227)。我们不管这个候选region的尺度或是纵横比,直接将所有的像素warp到一个bounding box中变成需要的大小。在warp之前需要dilate这个bounding box,这样每个原始的box经过warp到特定size之后,正好是16像素。如图2所示。
test-time detection
测试阶段,我们在测试图片上使用selective search来提取2000个regionproposal。然后将每个proposal warp成固定大小,送入CNN中前向传播,计算特征。再将提取出的特征使用SVM计算属于每个类的分数。有了图片的所有region的分数,我们就能应用贪婪非极大值抑制,来去除和高分数的region的重叠面积大于阈值的region。
run-time analysis
- 所有类别上的所有CNN参数都是共享的
- 由CNN计算得到的特征向量是低维的(4096维)
共享参数的结果是,计算proposal和feature的时间被分摊到每一类上了。唯一的需要每个特定类的计算是:
- 特征和SVM权值之间的点乘
- 非极大值抑制
实际上,所有的点乘操作被batch到了一个矩阵和矩阵的乘法。特征矩阵通常是2000*4096维的,而SVM的权值矩阵是4096*N维的(N是类别数)。
通过以上分析,即便检测目标有100k类,我们的矩阵成大只需要10秒钟。
Training
Supervised pre-training
我们在一个大的辅助数据集上(ILSVRC2012 classification)pre-trained CNN 的参数,仅仅是使用图像级别的标注,没有bounding box的标注。
Domain-specific fine-tuning
为了适应检测的新任务和(warped proposal window)的新领域,我们继续使用SGD来训练CNN的参数。除了将CNN中用于ImageNet1000分类的分类层改成N+1层外,其他都没有变。
我们将与groundtruth的IOU>0.5的proposal视为正样本,其余的是负样本。SGD的学习率开始是0.001,既可以fine-tuning也不会破坏初始化。在每个SGD迭代过程中,我们统一采样32个positive window(在所有类别上)和96和background window来构建一个size为128的mini-batch。
注意:我们将采样偏向于positive window因为相比较于背景来说它们非常稀少。
Object category classifiers
比如现在要训练一个检测汽车的二分类器。显然一个包围了汽车的region一定是正样本。同样,和汽车毫无关系的region一定是背景。但是部分包含汽车的region该如何定义呢?我们定义了一个IOU的重叠阈值。不同的IOU阈值对于检测的mAP影响很大。这里设为IOU=0.3。
在appendix b中讨论了为什么训练SVM和fine-tune时候的正负样本定义不一样。
同时讨论了使用SVM来训练分类器而不是简单地使用fine-tunedCNN之后的softmax层输出的原因。
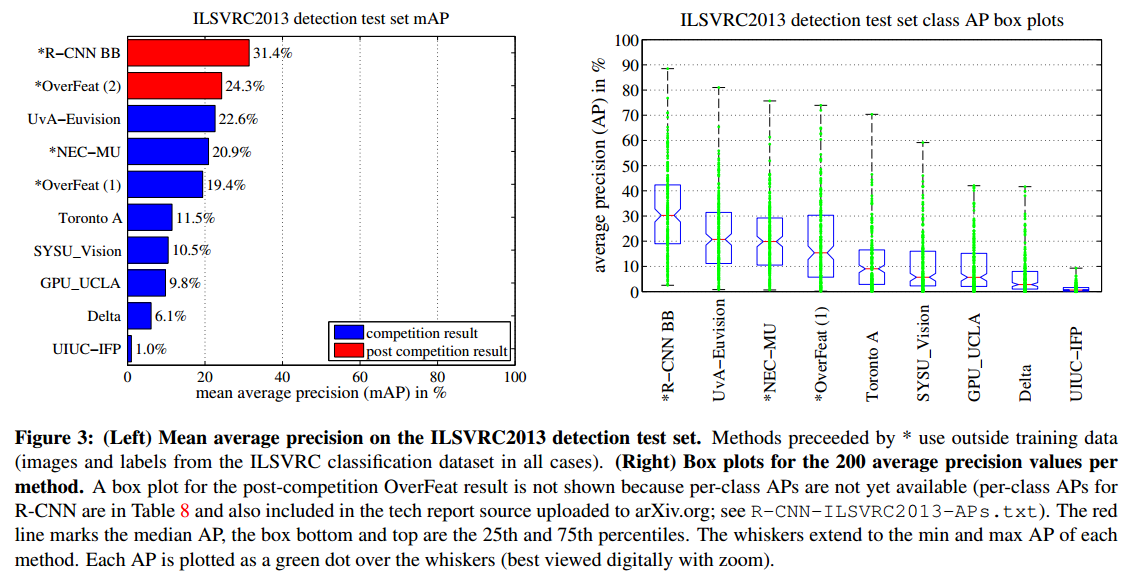
Results on PASCAL VOC 2010-12 and ILSVRC2013
Visualization, ablation, and modes of error
可视化学习到的特征
我们可视化网络第五层也是最后一层的最大池化层的输出单元。特征图大小是(6*6*256=9216)维的。忽略了边界效应后,每个池化单元有一个195*195的感受野。中心的pool5几乎有全局视野。通过显示的顶层16个激活单元输出来看,##网络学习到的特征表达是形状、纹理、颜色和物质特性的结合。接下来的第6层全连接层就是将这些丰富信息的特征建模##。
Ablation study
An ablation study typically refers to removing some “feature” of the model or algorithm, and seeing how that affects performance.