引言:
如果想要提高定位的准确性,就会面临两个问题:1.产生的proposal必须经过处理。2.这些候选框必须修正过才能达到精确定位。
本论文提出了一种联合地进行目标proposal分类和修正空间位置的方法。
RCNN的缺点
- 训练过程是多阶段的。RCNN首先在目标proposal上使用
log损失来fine-tune一个卷积网络;然后再去训练SVM;最后还要进行bounding box回归。 - 训练过程费时且占内存。对于SVM和bounding box训练,需要从每个object proposal里提取出特征在写入硬盘中。如果用了很深的网络比如VGG16,会占用很多存储空间,也很费时。
- 检测的速度慢。检测一张图片(VGG16)需要47秒。
RCNN很慢,因为它在每个proposal上都前传了一遍卷积网络,没有共享计算。
SPPNet是RCNN的加速版本,共享了卷积计算。SPPNet计算了一张整个输入图片的特征图,然后用一个从共享的特征图里提取出来的特征向量对每个目标proposal进行分类。通过在proposal内的feature map上进行最大池化操作,将特征提取出来并固定到固定大小(6*6)。多种输出尺寸首先进行池化然后再拼接。
SPPNet的缺点:
- 训练过程是个多阶段的过程,包括提取特征,用
log损失来fine-tune网络,训练SVM,最后进行bounding box回归。- 特征同样需要写入硬盘中。
- 与RCNN不同的是,SPP 中的fine-tune不能够在空间金字塔池化之前更新卷积层,因此限制了精度。
Fast RCNN的架构和训练方法
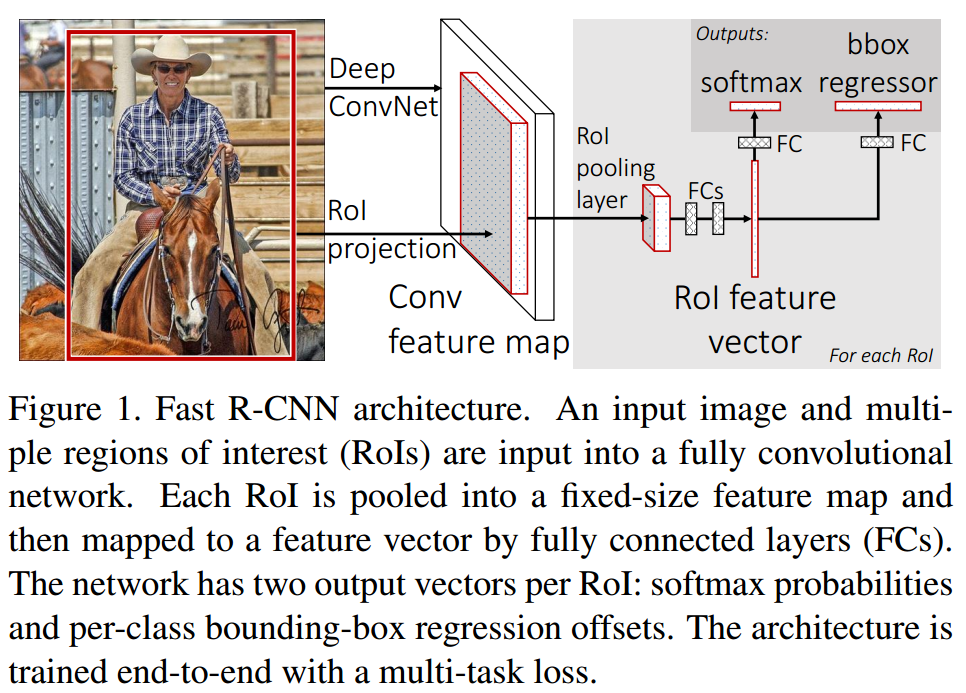
FastR-CNN网络输入一整张图片和一套object proposal。图像先经过几层卷积层和max pooling层产生一张特征图;然后对特征图进行ROIPooling,为每个object proposal提取出固定大小的特征向量;再将每个特征向量送入一序列全连接网络中,最后生成两个分支:一条产生softmax概率,估计K个目标和背景的类别;另一条为每个类别输出四个坐标。
ROI pooling层
RoI pooling层使用最大池化(max pooling)将有效的ROI的特征转化成小的特征图,都是固定大小(H*W),比如(7*7)。本文中,每个RoI有一个四元素的元祖定义,(r,c,h,w),(r,c)是左上角坐标,(h,w)是高和宽。
RoI max pooling 将一个(h*w)的RoI窗口分成(H*W)的网格,每个网格大小接近(h/H,w/W)。然后对每个子网格进行最大池化操作输出网格单元。池化操作在每个特征图通道上独立进行。这个RoI层就是SPPnet里面空间金字塔池化的特例,这儿只有一个金字塔层。所有在子窗口上的池化操作都是按照SPPnet中给出的方法进行的。
从预训练的网络中初始化
我们试验了3中在IamgeNet上预训练的网络,每个有5层max pooling层和5~13层的卷积层。当使用这三种网络进行初始化Fast RCNN网络时,经历了三种变换。
- 最后一层max pooling层被换成了RoI pooling层,宽高被设置成了
H和W,为了和网络第一层的全连接层兼容(VGG16中H=W=7)。 - 网络最后一层全连接层和softmax层(ImageNet分类中有1000类)被替换成了两个并列层。
- 网络输入有两个:一系列图片,一系列ROI输入。
Fine-tuning for detection
SPPnet在空间金字塔池化层下不能更新权重的根本原因是:当一个训练样本来自不同的图片时,后向传播是很没有效率的。因为每个ROI有一个很大的感受野,通常横跨了整个输入图片。前向传播必须处理整个感受野,因此训练数据也经常是整张图片。
我们提出的训练方法更有效,利用了特征共享。首先采样$\textbf{N}$张图片,然后从每张图片采样$\textbf{R/N}$个ROI,进行SGD。重要的是,**来自相同图片中的RoI在前向和后向传播时都会共享计算和存储资源。当$\textbf{N}$变小则会减少mini-batch的计算。比如,$N = 2$和$R = 128$的时候,该训练策略会比RCNN快64倍。
有人担心这样收敛速度会变慢,因为同一张图片的ROI会相互关联。事实证明并不会,在$N = 2$和$R = 128$的情况下我们达到了更好的结果,且SGD迭代次数也比RCNN少。
Fast RCNN可以联合优化softmax分类器和bounding box回归器,而不是分为三个步骤(训练softmax分类器,SVM,和回归器)。下面详细介绍:
Multi-task loss
FastR-CNN网络有两个并列输出层。第一个输出每个RoI的一个离散概率分布,$p = (p_0,…,p_K)$,在$K+1$个类别上。$p$是由一个softmax在一个全连接层的$K+1$个输出上计算得到的。第二层输出了bounding box的回归偏差。$t^k = (t_x^k,t_y^k,t_w^k,t_h^k)$,$k$是索引,一共有$K$个类。我们使用RCNN中的参数优化方法,$t^k$是个尺度不变的平移变换并且对数域的高度/宽度变换,相对于目标proposal。
每一个训练的ROI被标记成groundtruth的类别$u$和bounding box的回归目标$v$。我们使用一个多任务的损失来联合训练分类和回归:
$$\textbf{L}(p,u,t^u,v)=\textbf{L}{cls}(p,u)+\lambda[u\ge1]\textbf{L}{loc}(t^u,v)\qquad (1)$$
其中,$\textbf{L}_{cls}(p,u)=-log(p_u)$是真实类别$u$的对数损失。
第二个损失$\textbf{L}_{loc}$是bounding box回归的损失对于类别$u$,$v=(v_x,v_y,v_w,v_h)$,和预测出的$t^u=(t_x^u,t_y^u,t_w^u,t_h^u)$。$[u\ge1]$表示忽略背景$u=0$的损失。
对于bounding box回归,我们使用一下损失:
$$\textbf{L}{loc}(t^u,v)=\sum{i\in {x,y,w,h}} smooth_{L_1}(t_i^u-v_i)\qquad (2)$$
其中:
$$smooth_{L_1}(x)=\begin{cases} 0.5x^2\quad if\ |x|\leq1\|x|-0.5\quad otherwise,\end{cases}\qquad (3)$$
这个$L_1$损失比RCNN和SPPNet里面用的$L_2$损失对异常值不那么敏感。
公式(1)中的$\lambda$控制了两个损失之间的平衡。我们将回归目标的$v_i$归一化到均值为0,方差为1.所有实验的$\lambda=1$。
Mini-batch sampling
在fine-tune过程中,每个SGD mini-batch由$N=2$张图片构成,每张图片采样64个RoIs,即$R=128$。和RCNN一样,25%的RoIs是由和groundtruth的IoU重叠大于0.5得到的。这些RoIs包含了前景目标类别的例子,即$u\ge1$。剩下的RoIs由和groundtruth有最大IoU的object proposal采样得到,IoU在$[0.1,0.5)$内。背景样本标记为$u=0$。
训练时,将图片水平翻转来做图像增强。
Back-propagation through RoI pooling layers
假设每个mini-batch里只有一张图片。让$x_i\in \textbf{R}$作为输入到RoI pooling层的第$i$个激活,让$y_{rj}$作为第$r$个RoI的第$j$个输入。RoI pooling层计算$y_{rj}=x_{i^*(r,j)}$,其中,$i^*(r,j)=\text{arg}\max_{i’\in \textbf{R}(r,j)}x_{i’}$。$\textbf{R}(r,j)$是输出单元$y_{rj}$最大池化上的输入的索引集合。一个单独的$x_i$可能被分配到不同的输出$y_{rj}$上。
RoI pooling层的后向传播函数计算了损失函数对每个输入变量$x_i$的偏微分:
$$\frac{\partial L}{\partial {x_i}}=\sum_r\sum_j[i=i^*(r,j)]\frac{\partial L}{\partial y_{rj}} \qquad (4)$$
换句话说,对于每个mini-batch RoI$r$和每个pooling的输出单元$y_{rj}$,微分$\frac{\partial L}{\partial y_{rj}}$会不断积累,如果$i$是由最大池化操作挑出来的最大值。在后向传播中,偏微分$\frac{\partial L}{\partial y_{rj}}$在输入RoI pooling层时已经计算好了。
SGD hyper-parameters
全连接层使用的softmax分类和bounding box回归由一个服从均值为0、标准差为0.01和0.001的高斯分布来分别初始化。偏直也被初始化为0。每一层权重的学习率为1、偏置的学习率为2,总体的学习率为0.001.
当在VOC2007或者VOC2012上训练时,我们在30kmini-batch上跑了SGD,然后把学习率降到0.0001又训练了10k次。在更大的数据集上训练时,需要迭代更多次。动量为0.9,参数学习率衰减为0.0005.
Scale invariance【待补】
Fast R-CNN detection
一旦Fast RCNN网络被fine-tuned好后,检测就相当于是一个前向传播的过程(假设object proposal已经给算好了)。网络输入一张图片和一系列$R$个object proposal。测试环节,$R$通常是2000。
对于每个测试的RoI$r$,前向传播先输出一个类的后验概率分布$p$和一堆预测的bounding box偏移量。我们把每个类$k$的检测的置信度置为$r$,使用概率分布$Pr(class = k | r) =^\Delta\ p_k$。然后对每个类独立的用非极大值抑制。
对于整张图片的分类,计算全连接层的时间比计算卷积层的时间短很多。相反的,检测过程中,RoI的数目很大几乎一半的时间都在处理ROI。因此使用了SVD分解来压缩全连接层来加速。
Main Result
Experimental setup
使用了三个预训练的网络:AlexNet、VGG CNN M 1024和VGG16
fine-tune哪一层比较好
对于SPPnet只用fine-tune最后一层全连接层。但是对于VGG16,从conv3_1开始往后的卷积层fine-tune效果最好。