Mask RCNN能够检测目标,同时产生一张高质量的分割掩模。它是在Faster RCNN基础上添加了一个与bbox识别平行的分支,来预测目标的掩模。运行速度5fs,并且可以泛化到其他的任务上:实例分割,目标检测,姿态估计。
论文框架
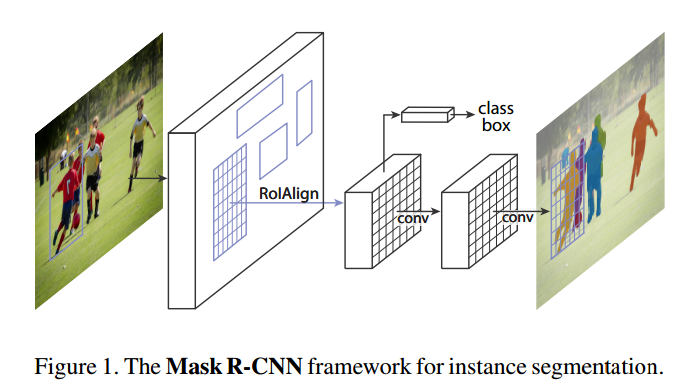
Mask 分支:对每一个感兴趣区域(ROI)预测分割掩模,利用了一个小的全卷积网络FCN .
Faster RCNN分支:原始Faster RCNN结构,对候选窗口进行分类和bounding box回归。
回顾:包括两个阶段,第一阶段为RPN阶段,提议了候选目标框。第二阶段是Fast RCNN阶段,通过ROIPool给每个候选框提取特征,并且执行分类和回归。两个阶段的特征是共享的,这样在前向推断时可以更快。
Mask RCNN
以往的语义分割方法都是基于掩模的预测来进行分类。Mask RCNN则是在分类、回归的同时,并行得为每个ROI输出一个二值掩模。
损失函数:
$$\textbf{L} = \textbf{L}{cls}+\textbf{L}{box}+\textbf{L}_{mask}\qquad (1)$$
mask分支在每个ROI有一个$Km^2$输出。表示$K$张(类别数)$m\times m$表示分辨率的掩模图。为每个像素定义一个sigmod函数,这样$\textbf{L}_{mask}$就是平均二值交叉熵损失。定义groundtruth 时,对于类别$K$,只定义$K-th$掩模。
这种定义分割损失的方式使得在类别之间不会有竞争,解耦合了掩模和类别预测。语义分割方法FCN,使用单像素的softmax多项式交叉熵损失,这样类别之间的mask会存在竞争,而我们所定义的单像素的sigmod二值交叉熵损失就不会。
Mask Representation
不像类别标签和box偏移最后会通过全连接层变成一个短的输出向量,掩模因为包含了输入目标的空间分布信息,需要通过卷积来点对点的提取空间结构。我们使用FCN来为每个感兴趣区域预测一个$m\times m$的掩模。这样就能保留空间信息。
全连接VS全卷积:以前的方法都是通过fc层来实现掩模预测,我们使用的全卷积表达需要更少的参数,并且精度更高。
ROIAlign
ROIPool:将浮点数分辨率的ROI量化成离散粒度的特征图,然后将量化后的ROI分成几个空间小块(spacial bins),然后每个小bin通过max pooling进行挑选。通过计算[x/16]在连续坐标x上进行量化,其中16是特征图的步长,[ . ]表示四舍五入。这些量化引入了ROI与提取到的特征的不对准问题。由于分类问题对平移问题比较鲁棒,所以影响比较小。但是这在预测像素级精度的掩模时会产生一个非常的大的负面影响。
举例:输入$800\times 800$的图片,一个bounding box为$665\times665$的小狗,经过VGG16特征图变为$50\times50$,但是bounding box变为$41.5625\times41.5625$,ROIpooling将他量化为41,接下来将框内的特征池化成$7\times7$的大小,显然每个矩形边长为5.86,再次被量化成边长为5,经过两次量化,出现很明显的偏差,0.1像素对应1.6像素的偏差,影响很大。
将提取的特征与输入对齐:避免使用离散化操作,直接使用$x/16$而不是$[x/16]$.使用双线性插值在每个ROI采样的四个位置计算输入特征的精确位置。具体操作:
- 遍历每个候选框,保持浮点数边界不做量化
- 将候选框划分为$k\times k$个单元,每个单元边界不量化
- 每个单元内计算四个坐标的位置,双线性插值,最后进行最大池化操作
网络架构
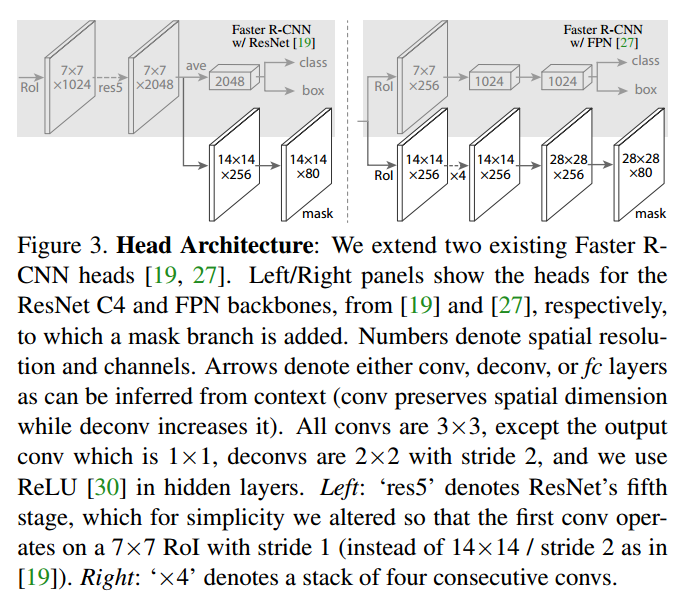
ResNet50
FPN:使用自上而下,横向连接的范式构建了一个内联的特征金字塔。
实现细节
Training
Fast RCNN中,ROI与ground truth的IOU大于0.5,则认为是正的,否则为负。$\textbf{L}_{mask}$只在正的ROI定义。细节:
- resize尺寸:短边800
- 每个GPU的mini-batch有两张图,每张图采样N个ROI,(ResNet C4为64,FPN为512),正负比例1:3。
- 8GPU(mini-batch为16),160k次迭代,学习率0.02,在120k次是变成0.002,weight decay为0.0001,动量0.9。
- RPN的anchor尺寸扩展到5个尺寸:$32^2,64^2,128^2,256^2,512^2$,3个长宽比:$1:2,2:1,1:1$.
Inference
proposal 数量:C4为300,FPN为1000.我们在这些proposal上进行box预测,在进行非极大值抑制。在得分最高的100个box上进行mask的预测,和training过程不同,但是可以加速并提高精度。Mask分支为每个ROI预测$K$个mask,我们只使用预测出的类别$k$,即$k-th$张。$m\times m$的mask输出最后被resize成ROI的大小,并且使用阈值0.5进行二值化。
实验
实例分割


FCIS: 通过全卷积预测位置敏感的输出。
优点:可以同时解决目标类别,位置,和掩模问题。
缺点:重叠的实例会产生虚假的边
Multinomial vs. Independent Masks:

FCN将分割和分类预测的任务耦合在了一起,最后AP低了5.5
表明:一旦实例通过box分支之后,将他看作一类,不用考虑他的类别,这对于预测二值化的mask来说足够了。也更容易训练。
ROIAlign


bounding box result

Human Pose Estimation
