Cascade RCNN
Author:Lanfang Kong
Email:kong875387859@outlook.com
CVPR2018的一篇论文,主要讲不同IOU阈值训练的级联检测器极大提升了目标检测的性能。
摘要
目标检测中,使用IOU来定义正负样本。一个使用低IOU(比如0.5)训练的目标检测器通常会产生noise detection。但是,当IOU阈值上升,检测器的性能有会下降。原因是:
- 训练时过拟合。 因为IOU上升,正样本数呈指数下降。
- 检测器最优的IOU和输入假设的IOU之间的前向推断时间不匹配。
CascadeRCNN是一个多阶段的检测框架,包括一组使用上升IOU训练的检测器,从而对close false positives更具有选择性。这组检测器是一个阶段接一个阶段训练的。通过重采样逐渐改进的假设,保证了所以检测器都能有相等数量的正样本,从而减少过拟合。 CascadeRCNN在COCO数据集上的性能比任何一个单模型的检测器都要好。
引言
目标检测问题的两个任务:首先识别问题,在背景中把前景目标区分出来并且给他分配合适的类别标签;其次,必须解决定位问题,准确定位不同目标的边界框。检测器要处理许多close false positives(就是离得很近但是不是正确的边界框)。
two-stage detector:RCNN框架的,通常使用的IOU=0.5,最后的检测器会产生很多noise bounding box,如图1a。有很多人在一起的情况就会使得许多close false positives在前传时的IOU>0.5.也就是说这个标准太单一化了。
定义假设框和GT的IOU作为假设的quality,定义训练时候使用的IOU u作为detector的quality。本文的目的就是要研究高质量的检测器,能够输出很少的close false positives,如图1b。基本的idea是一个单独的detector只能对一个单个的quality level进行优化。在cost-sensitive 学习特征时,优化ROC曲线上不同点的优化需要考虑不同的损失函数。我们和他的不同就是考虑给定IOU的阈值进行优化,而不是false positive rate。
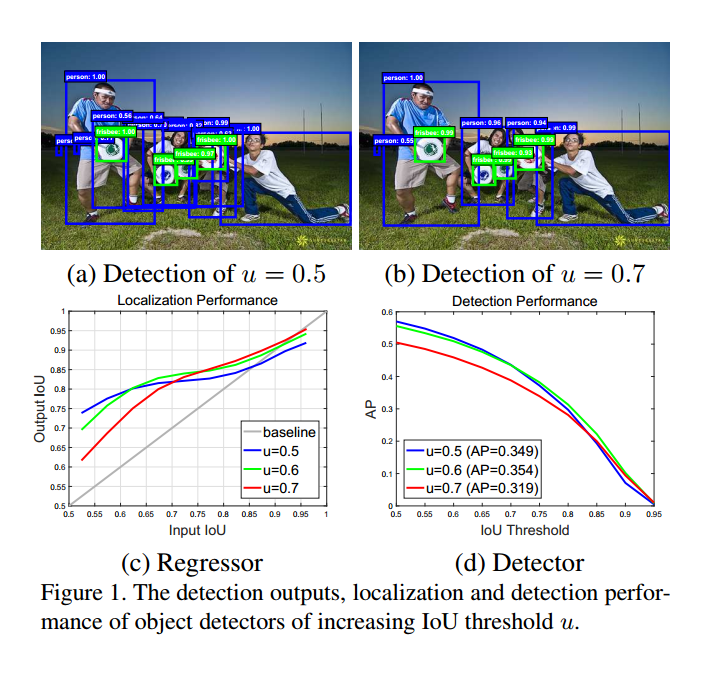
上图c,d中显示了我们使用不同IOU阈值训练的地三个检测器的定位和检测性能。
图c:
- 在图c中,横轴是输入proposal的IOU,纵轴是经过bbox回归之后的bbox和GT的IOU.
- 可以看出,低IOU阈值训练对于低IOU的样本有更好的改善,但对于高IOU的样本就不如高阈值训练的有用。
- 所有的曲线都在灰色线上方,说明回归器的输出的IOU总是比输入的IOU好。
图d:
- 图d显示阈值u=0.5的检测器的效果比u=0.6的检测器的效果在低IOU的样本上会更好。
一般来说,在一个单一IOU上进行优化的检测器并不是在其他层次上都是最优的。也就是说,想要更高质量的检测,就需要检测器和假设之间更加接近的匹配。一般来说,检测器有了高质量的proposal之后才能拥有高质量的性能。
但是,简单的在训练中提高阈值并足够提高检测器的性能。但是当u=0.7的时候,性能却下降了。因为假设分布通常严重不均衡,倾向于低质量的样本。在训练时,使用更大的IOU往往会导致正样本的指数级下降。
本文的想法是,一个阶段的输出用来训练下一个阶段,因为回归器的输出的IOU总是比输入的IOU好。从图1c可以看出来,因为所有的曲线都在灰色线上方。这个跟boosttrapping很像,主要的不同是,cascade RCNN的重采样过程不是为了挖掘难样本,而是为了调整边界框,为训练下一个阶段挑选出一组好的close false positives。 这样可以避免过拟合。
本文的方法只用了一个简单的思想牺牲了一些精度,就达到了大幅度的精度提升。
2.Related Work
两阶段的目标检测方法:
- RCNN
- SPP-Net
- Fast RCNN
- Faster RCNN
- RFCN:提出了region-wise的全卷积且没有精度损失,避免了Faster RCNN中严重的region-wise的CNN计算。
- MS-CNN,FPN
一阶段的目标检测方法:
这些方法的框架接近于滑动窗机制。。。。
- YOLO:优点: 检测时候只用前传图片一次。实时但是精度一般。
- SSD:思想:类似RPN,但是使用不同分辨率的特征图来cover不同尺寸的目标。不足: 比两阶段精度低
- RetinaNet:解决了前景-背景的极度类别不均衡,比两阶段的结果好。
多阶段的目标检测方法:
- Object detection via a multiregion and semantic segmentation-aware CNN model. 迭代的边界框回归,来产生更好的边界框
- ……
3.Object detection
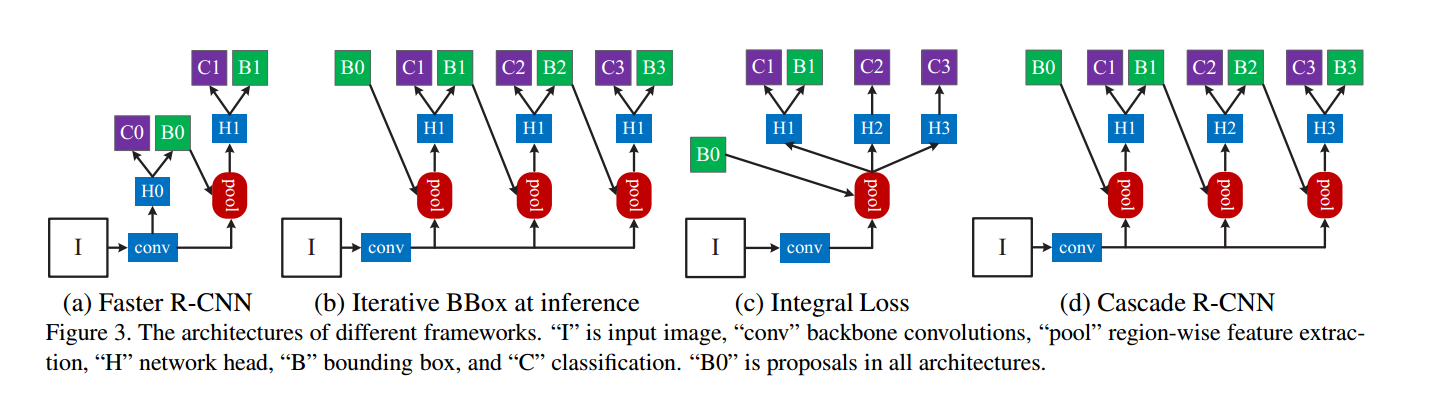
如下图a,第一阶段是个proposal sub-network(不知道咋翻译。。。。。),H0,作用在整张输入图片上,产生原始的检测假设集合,也就是proposal。第二阶段,这些proposal被送入roi检测子网络H1,记做detection head。会给每个proposal分配一个分类分数C和一个边界框B.我们着重建模易分多阶段的detection sub-network检测子网络,且采用了不止RPN这一种网络来产生proposal。
3.1 Bounding box regression
candidate bounding box:$\textbf{b}=(b_x,b_y,b_w,b_h)$
target bounding box:$\textbf{g}$
回归器:$f(x,\textbf{b}_i)$ ,从一个训练样本${\textbf{g}_i,\textbf{b}_i}$学习,
目标函数:
$$
R_{loc}[f]=\sum_{i=1}^NL_{loc}(f(x_i,\textbf{b}_i),\textbf{g}_i)\qquad(1)
$$
$L_loc$是$L_2$损失函数(RCNN中)。smooth$L_1$函数(FastRCNN中)。
为了使得回归对尺度和位置具有不变性,$L_{loc}$的作用对象是一个向量$\Delta=(\delta_x,\delta_y,delta_w,\delta_h)$定义如下:
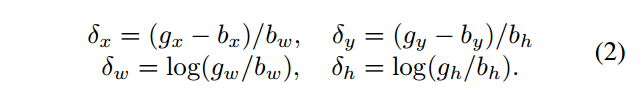
边界框回归在执行的时候,对$b$的调整都是很微小的,因此这里的risk比分类的risk小的多(risk是什么意思啊……风险???)。为了提高多任务学习的效率,$\Delta$被归一化了(均值方差)。$\delta_x’=(\delta_x-\mu_x)/\sigma_x$ .
iterative BBox:迭代的边界框回归方法
有些人认为,我们的回归步长$f$设的太小了对于精确定位不够。于是,$f$是迭代应用的,作为后处理步骤。
$$
f’(x,\textbf{b}=ff……*f(x,\textbf{b}))\qquad(3)
$$
来微调边界框$\textbf{b}$,这叫做迭代的边界框回归,记作iterative BBox .推断框架如图3(b),其中,所有的head网络都一样。但是有两个问题:
- 如图1,回归器$f$是在阈值$u=0.5$训练的,对于更高的IOU的假设集合来说不是最优的。对于IOU大于0.85的边界框来说拉低了性能。
- 如图2,边界框的分布在每一次迭代后会变换剧烈。回归其对初始的分布来说是最优的,但是之后的就不是。
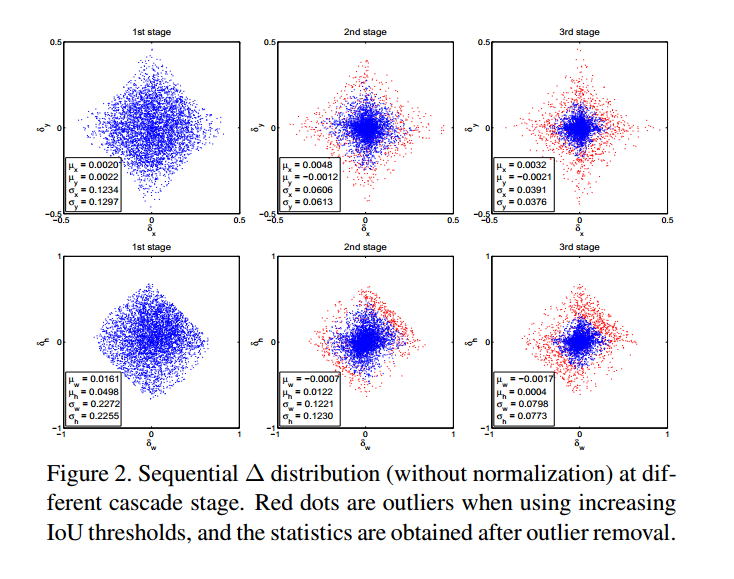
缺点: 需要大量人工,比如proposal 积累,box投票。还没啥用,通常迭代liangci$f$就不会有用了。
3.2Classification
分类器:$h(x)$.是$M+1$维的,是类别的后验分布的估计。例如:$h_k(x)=p(y=k|x)$. 其中,$y$是类别标签。分类任务:
$$
R_{cls}[h]=\sum_{i=1}^NL_{cls}(h(x_i),y_i)
$$
其中$L_{cls}$是交叉熵损失。
3.3Detection quality
一般一个边界框包含目标和背景,很难区分是正样本还是负样本。通常设定IOU阈值来确定:
$$
y=\begin{cases}g_y,\quad IoU(x,g)\ge u\0,\quad otherwise\end{cases}\qquad(5)
$$
$g_y$是GT $g$的类别标签
u的设置矛盾:
当u大的时候,正样本包含的背景少,但是很难集合足够多的正样本训练样本。
当u小的时候,有更加丰富的多样的正样本训练集合,但是检测器会更难区分排除close false positives.
一般来说,很难让单个的分类器在所有IOU上表现的一样。前向推理时,因为RPN汇总selective search产生的大部分proposal都是低质量的,因此后面的检测器需要更具有判别能力。一个这种的做法就是设置$u=0.5$。但是这个阈值很低,使得检测的质量不高,就像图1(a)中的close false positives.
integral loss:整行不同IOU阈值下的分类损失:
一种简单的做法就是图1(c).提出一种分类器集合。优化不同quality level的损失。
$$
L_{loc}(h(x),y)=\sum_{u\in U}L_{cls}(h_u(x),y_u),\quad(6)
$$
其中$U$是IOU阈值的集合。比如$U={0.5,0.55,……,0.75}$. 这是为了适应COCO的评价方式。
缺点:
- 没能解决不同正样本数量下损失不同的问题。
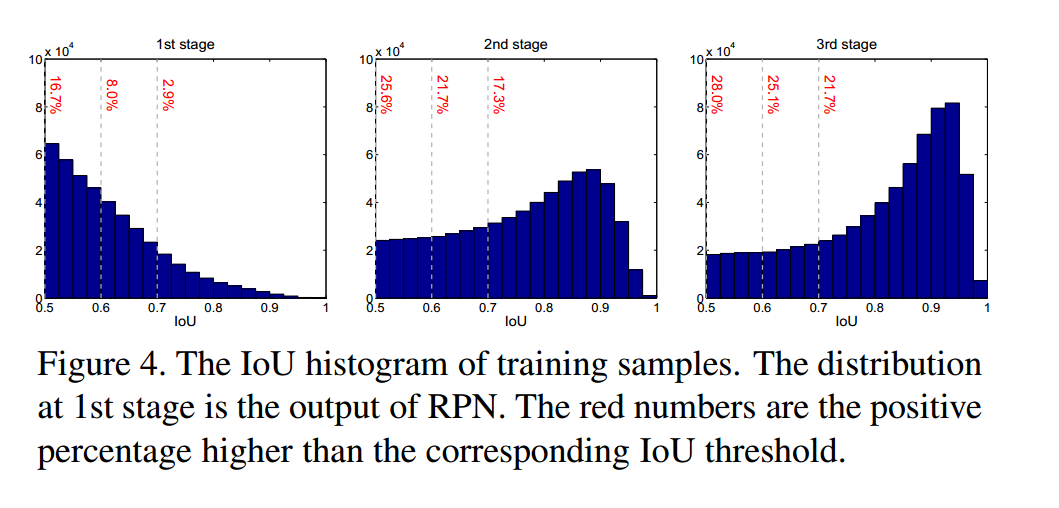
- 如图4中第一张图所示,u升高的话正样本数目会很快减少。会导致过拟合。
- 前向推断时,需要处理大量低质量的proposal,不是他们在训练时候优化的那种。
这种方法提升微乎其微。
4.Cascade RCNN
4.1Cascaded bounding box regression
经cascade pose regression和face alignment激发,提出了级联RCNN.
如图3(d):
$$
f(x,\textbf{b}=f_Tf_{T-1}……*f_1(x,\textbf{b})),\qquad(7)
$$
$T$是总共的级联数目。注意每个回归器$f_t$是由到达相应阶段的采样分布来优化的,不是初始的分布{$\textbf{b}^1$}.
与iterative bbox不一样:
- iterative Bbox框架如图3(b),是一个后处理的过程,而级联回归则是重采样的过程,改变了不同阶段的假设分布。
- 在训练和前向推断时候都要用到,因此两个阶段没有差别矛盾(也就是说前向时候不会出现大量的close false positives,比训练的时候多得多的情况)。
- 回归器$f_T,f_{T-1},……,f_1$,是在不同阶段对重采样后的分布进行优化的,和式子(3)有本质不一样(式3是支队初始分布进行优化)。
这种方法使得毕iterative bbox有更加准确的定位。
同时,为了多任务学习的效率,每个阶段的$\Delta=(\delta_x,\delta_y,\delta_w,\delta_h)$ 在式2中都是经过均值方差归一化的。每次回归过程之后,这些数据也会变化,就像图2所示。在训练时,这些数据就会用来归一化每个阶段的$\Delta$.
4.2Cascaded Detection
如图4左边,初始假设集的分布是RPN的proposal,倾向于低质量的proposal。
cascade RCNN通过resampling mechanism来解决这一问题。基于事实:图1c中所示,所有的曲线都在对角灰色线的上方,也就是说一个特定$u$训练的边界框回归器往往能够产生更高IoU的边界框。因此,开始时样本集合$(x_i,\textbf{b}_i)$,级联的回归器能够重采样一个更高IoU的样本分布。所以可以将连续阶段的正样本的尺寸保持固定。
如图4后,每次重采样之后,分布会朝向高质量的样本。
- 不再有过拟合,因为每个阶段的样本都很充足
- 更深阶段的检测器使用更高的IOU进行优化
- 在图2中可以看出来,一些异常点会被删除,使得训练的检测器更好
每个阶段$t$,RCNN包含了一个分类器$h_t$和一个回归器$f_t$,优化的阈值是$u^t$,且$u^t>u^{t-1}$, 优化以下损失可以保证这一点:
$$
L(x^t,g)=L_{cls}(h_t(x^t),y^t)+\lambda[y^t>=1]L_loc,\qquad(8)
$$
其中$\textbf{b}^t=f_{t-1}(x_{t-1},\textbf{b}^{t-1})$, $g$是$x^t$的ground truth的目标。$\lambda=1$.并且$y^t$是给定$u^t$下$x^t$的标签(式5)。不像intergral loss 式(6),这点能够保证训练的检测器质量越来越高。在前向推断时,由于应用了级联检测器,假设集合的质量也在逐渐提高,并且高质量的检测器只会作用于高质量的假设集合上。
5.实验结果
MS-COCO2017有118k张训练图片,5k张验证集和20k的测试集。COCO在测评的时候通常使用IOU(0.5~0.95)阈值来计算平均精确度,间隔为0.05.
5.1实现细节
为了简单,所有的回归器都不考虑类别。所有的级联的检测阶段都有相同的架构。cascade RCNN总共有4个阶段:一个RPN和3个检测阶段 。($U={0.5,0.6,0.7}$).第一个检测阶段的采用和Faster RCNN中一样,下面的两个阶段,重采样是由之前阶段回归器的输出实现,和4.2节一样。数据增强只是用了水平翻转。前向推断实在单一的图像尺寸上实现。
5.1.1基础网络
Faster RCNN(VGG-net)
R-FCN,FPN(ResNet)
都是end-to-end training
各实现细节见论文。。。
5.2Quality Mismatch
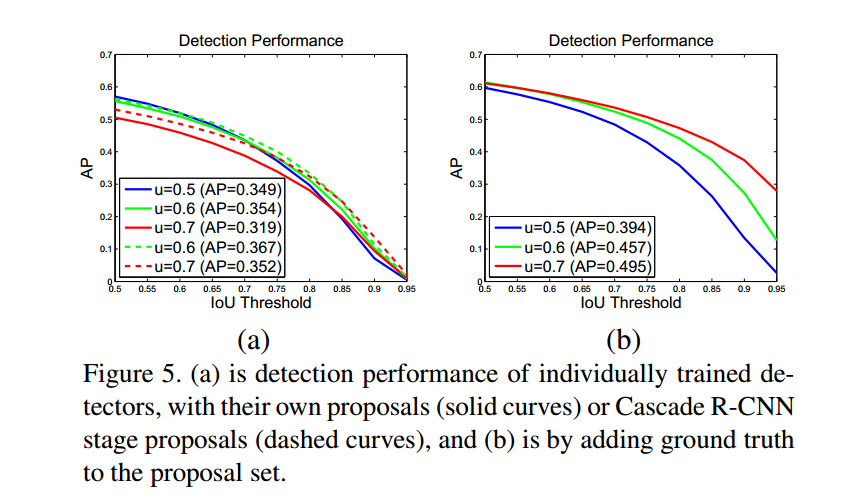
该图5(a)显示的是使用上升阈值$U=0.5,0.6,0.7$单独训练的检测器的AP曲线。$u=0.5$训练的检测器在IOU低的阶段比$u=0.6$的效果好,但是在高iou时效果降低了。$u=0.7$训练的检测器效果比其他两个都差。
图5b显示了当groundtruth proposal加入时,的结果。所有的检测器都提升了,且$u=0.7$是提升的最多的。由此可知:
- $u=0.5$对于精确检测来说不适用,只是对低质量的proposal来说比较鲁棒。
- 高精度的检测器需要高质量的假设来匹配
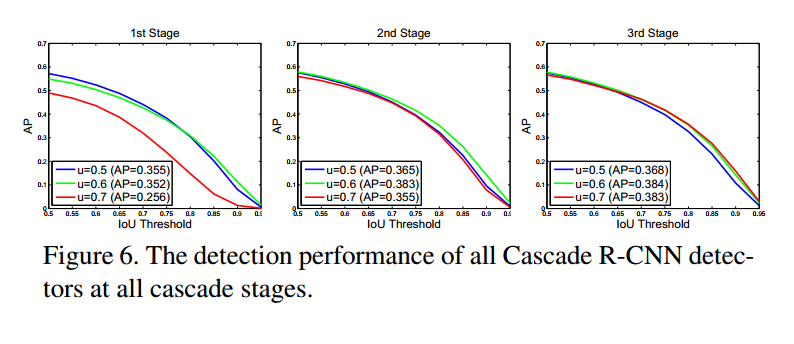
如图6,联合训练的检测器比单独训练的精度要高(图5a).
5.3和iterative bbox 回归比较
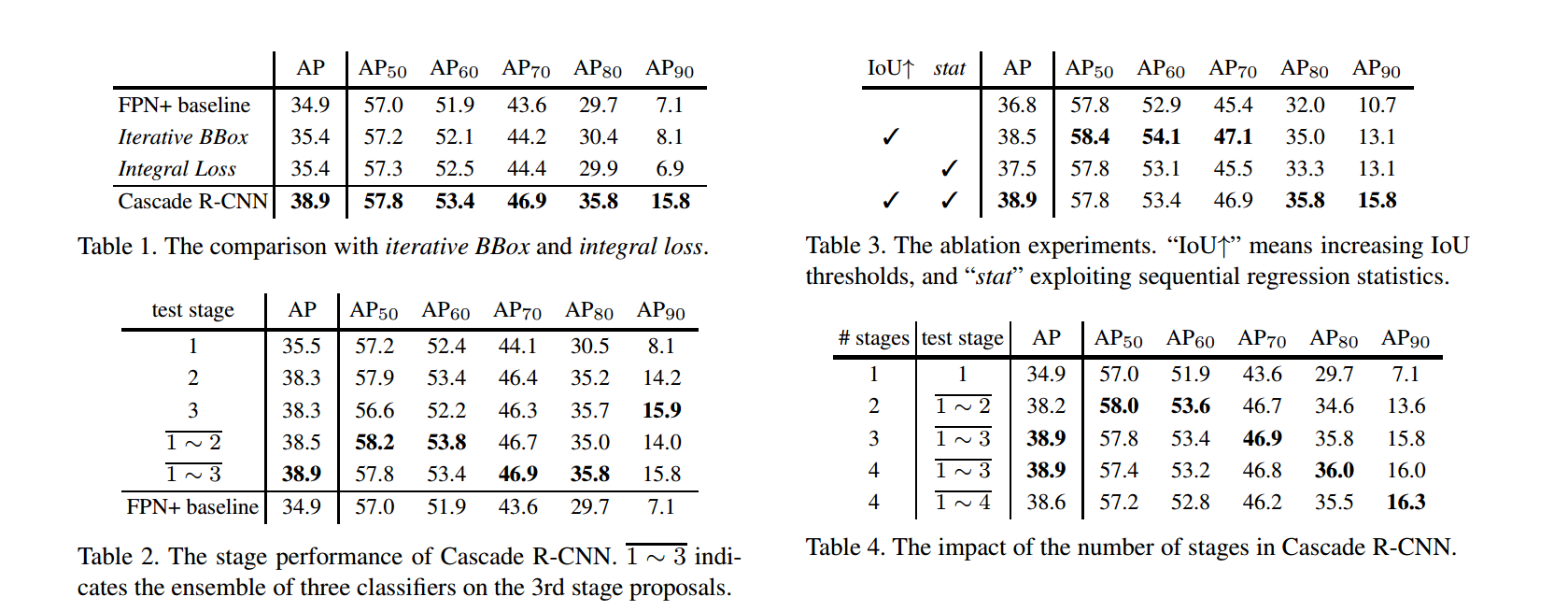
5.4和其他方法比较