YOLO3介绍
paper
效果
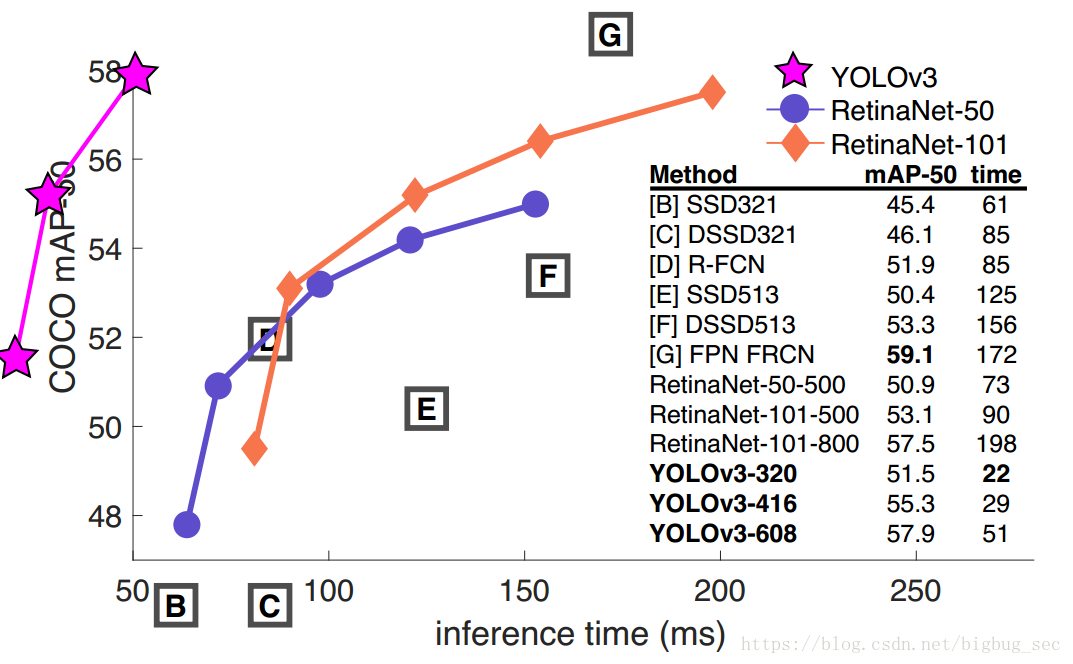
DarkNet53
YOLOv2使用的框架是DarkNet19,负责提取特征,再加上11层来进行目标检测。只有30层的网络结构对于小目标的检测来说很困难。因为网络中对输入进行了下采样,使得底层的精细化的特征丢失。所以v2使用了单位映射,把前面层的特征图拼接到当前层。但是,仍然没有一些比如残差块residual block,跨层连接skip connection,上采样upsampling这样的操作。
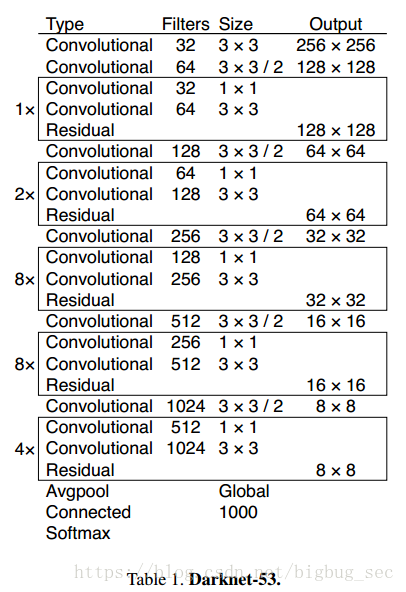
YOLO v3使用了53层预训练网络,然后又添加了53层进行检测,最后是106层的全卷积框架。 因此v3比v2慢。
yolov3的特征提取模型是一个杂交的模型,它使用了yolov2,Darknet-19以及Resnet,这个模型使用了很多有良好表现的$3\times3$和$1\times1$的卷积层,也在后边增加了一些shortcut connection结构。最终他有53个卷积层,因此作者也把它们叫成Darknet-53。它们的结构是这样的:
最后论文说明这个模型的优良之后还说了一句,Resnet模型后边有太多层并且不是很有效。
Multiscale detection
YOLOv3在3个尺度行进行检测。

ü检测时的卷积核大小为1 x 1 x(B x (5 + C) ).B是一个cell的Bbox的数目。YOLOv3上COCO上,B=3,C=80,所以卷积核大小是1 x 1x 255。
输入$416\times415$图片,三层的步长是32,16,8,也就是说预测的特征图是$13\times13,26\times26,52\times52$.第一次检测是在82层,在第81层会有一个步长为32,特征图尺寸是$13\times13$,然后经过$1\times1$的卷积核,得到检测特征图为$13\times13\times255$.
然后,第79层的特征图经过上采样,因子为2,变成$26\times26$,再和第61层的特征图通道拼接,经过几个$1\times1$的卷积层进行特征融合,最后第二个detection在第94层的特征图上进行,检测特征图为$26\times26\times255$.
第91层的特征图经过几个卷积层然后和第36层的特征图进行通道拼接,拼接的特征图经过几个$1\times1$的卷积层进行特征融合,最后在第106层进行最后一策检测,检测特征图为$52\times52\times255$.

作者说,这使得YOLOv3在检测小目标上的性能提升了。因为上采样的原因,可以和之前的layers进行拼接是的保留了精细化的特征,更好的检测小目标。不同尺度进行检测大、中、小的目标。
边界框的预测
全卷积网络
YOLO全是卷积层组成的,有75层卷积层,跨层连接,上采样层。
YOLO没有pooling层,直接使用一个步长为2的卷积层进行下采样。 这样可以防止丢失低层的特征。
作为全卷积层,YOLO对输入图像的尺寸不敏感,但是实际操作中必须固定输入尺寸避免一些问题,比如如果想批处理的话。
一般来说,网络的步长就是输出尺寸比输入小的倍数。
Interpreting Output
在YOLO中使用$1\times1$的卷积层输出的特征图进行预测。在特征图上,有$B\times(5+C)$个预测量,$B$表示在检测特定目标时,每个cell预测的bounding box数目 。每个bounding box有$5+C$个属性,表示中心坐标,维度,objectness score和C个类别概率。YOLO3每个cell预测3个bounding box.**
我们希望在特征图上,通过每个cell的一个bounding box预测目标的中心是否在这个cell的感受野内。在训练时候,给定目标,只有一个bounding box负责检测。我们首先得确定这个bounding box属于哪个cell。
举个例子:输入$416\times416$的图片,网络步长为32,最后特征图就是$13\times13$的,我们把输入图片划分成$13\times13$的。
包含groundtruth中心的那个cell来预测目标,图中就是那个红色的cell,包含了小狗的真实标签的中心。
Anchor box
预测bounding box的宽高在训练的时候会导致梯度传播不稳定。于是,利用对数域的变换,或者直接预测预定义的default box的偏移。YOLOv3每个cell有3个anchor。
每个尺度上,每个cell预测3个bounding box,(即3个anchor)。anchor总数为9.
也就是,和groundtruth拥有最高IOU分数的那个anchor来负责检测小狗。
Making Predictions

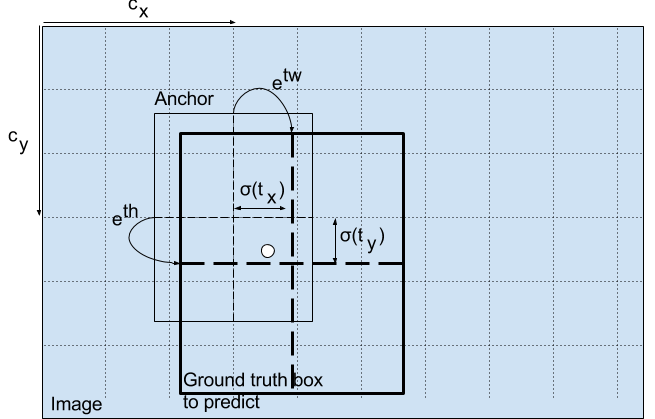
$t_x,t_y$是网络的输出,$c_x,c_y$是网格左上角的坐标,$p_w,p_h$是anchor的维度。$b_x,b_y,b_w,b_h$是预测的中心坐标,和宽高。
中心坐标预测:
输出经过了一个激活函数,使得输出在0-1之间,YOLO没有预测bounding box中心的绝对坐标,他是预测了偏移:
- 预测目标的那个网格,相对于左上角的坐标
- 然后该offset被该cell的宽高归一化
例如:小狗的中心预测是(0.4,0.7),那么在$13\times13$的特征图上就是(6.4,6.7)。但是如果偏移预测值是(1.2,0.7)咋办,那么对应的坐标就是(7.2,6.7)了,中心点就跑到了红色cell的右边,打破了yolo的规则:希望groundtruth中心所在的红色cell来负责预测小狗。 因此,为了防止这种事情发生,就将输出经过一个sigmod函数,强制变到0-1之间。
bounding box的维度预测:
应用对数域变换,再乘以anchor的维度。预测的结果是$b_w,b_h$ ,经过归一化了。
比如:例如$b_x,b_y$预测值是(0.3,0.8),那么真实的特征图上的宽高就是$13\times0.3,13\times0.8$。
Objectness Score
red cell及周围的cell的objectness score是约等于1,grid角落的几乎是0.
分类class confidence
v3之前的版本类别分数,是softmax函数,现在作者采用logistics函数。IOU分数也变成logisitic函数求得的。因为softmax预测的类别是互斥的。
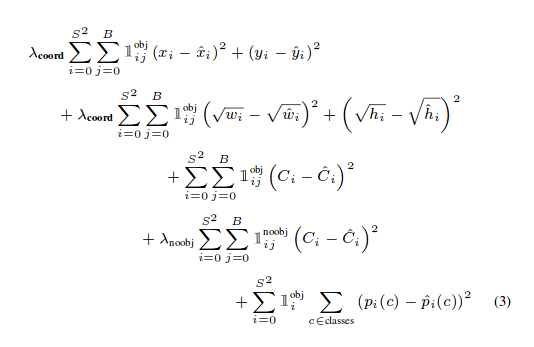
输出处理
对于$416\times416$的输入图片,YOLO预测了$((52\times52)+(26\times26)+(13\times13))\times3=10647$个边界框。当图中只有一个目标,怎么把检测从10674减到1呢。
- Object Confidence Threshold:低于阈值的忽略掉
- 非极大值抑制
作者总结
① 想对Anchor box的x,y偏移使用线性激活方式做一个对box宽高倍数的预测,结果发现没有好的表现并且是模型不稳定。
②对anchor box的x, y使用线性的预测,而不是使用逻辑回归,实验结果发现这样做使他们模型的mAP掉了。
③使用Focal loss,测试结果还是掉mAP。(想法的确挺好的)