作者:konglanfang
大规模数据集上训练的detector比较少,本文总结了两个一阶段和二阶段的large-scale detector,并附上自己在Google open image目标检测赛道的比赛经验。
一、RFCN3000
1.RFCN回顾
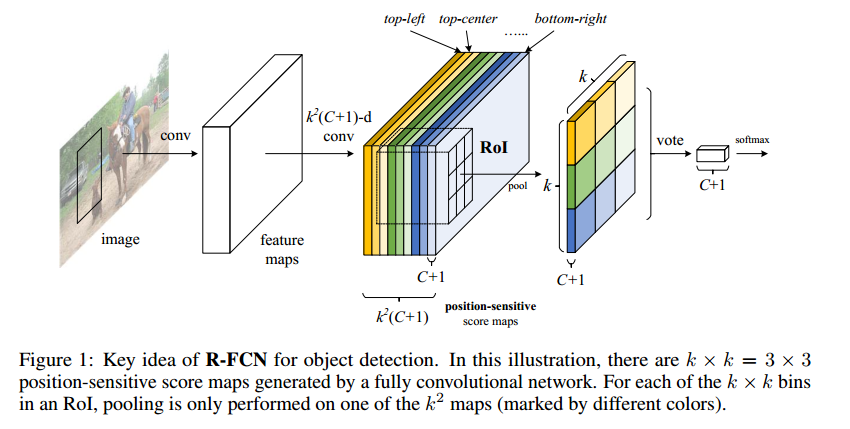
一般来说,网络越深,其具有的旋转平移不变性越强,这种特性对于分类来说有积极意义,但是对于检测任务而言,会削弱定位的精度,因为检测模型需要对位置信息具有良好的感应能力。因此在faster rcnn中,为了防止网络深度使得网络对位置的敏感度下降,RPN网络一般会向浅层特征图移动,然后再做roi-wise的分类和回归任务。但是这样明显会增加计算量。
RFCN网络是为了提高Faster RCNN的速度而提出来的,以resnet101为backbone的网络为例,faster rcnn中roi pooling的输入是在conv4_x,做完roi pooling之后还要送入conv5_x(包含9层),再还有几个全连接层。这些层作用在每个ROI上,所以会有大量重复计算(VGG16为backbone的要好些,只有两个全连接层的重复计算)。
R-FCN: 将faster rcnn中roi-wise的卷积计算都挪到ROI Pooling之前,力求实现层共享。一方面,将conv5_x的卷积计算挪到pooling层之前,然后再引入position-sensitive score map和ps roi pooling来之后需要通过在卷积层的最后一层特征图上应用$k^2(C+1)$个$1\times1$的卷积核,生成$k^2(C+1)$张位置敏感的特征图。其中:$k^2$表示一个roi中的感应位置个数,$C+1$表示类别数,特征图被分成了$C+1$个组,每组有$k^2$张特征图。进行ps-pooling操作时,每个类别对应的位置区域的特征图经过全局平均池化得到$C+1$维向量,在进行投票得到类别分数,计算分类损失。RFCN在精度较fasterRCNN提高的同时,速度也提升了3倍左右。
2.R-FCN3000
tag:
- Large Scale Fully-Convolutional Detector
- Decoupling Detection and Classification
- trained on the ImageNet classification set with bounding-box supervision
- 30fps
- super class,k-means
- ……
网络架构:
RFCN的弊端也很明显,当类别数很大时,生成的ps-score map的维度也要相应增多,计算量很大。因此,本文的重点就是将类别数提高到3000类的同时,通过共享卷积计算来减少卷积核数目,保证速度。
另外回归支路保持不变,因为回归与类别数无关(Faster RCNN中每个类别一个回归器,比如VOC数据集的回归支路的输出维度为$84$)。后来的大部分算法都设计成了前景和背景的两类的回归方法。所以类别数增加对回归支路没有影响。
RFCN3000是如何在增加类别数的同时,不增加计算量的呢?下面就介绍她是如何解耦的:
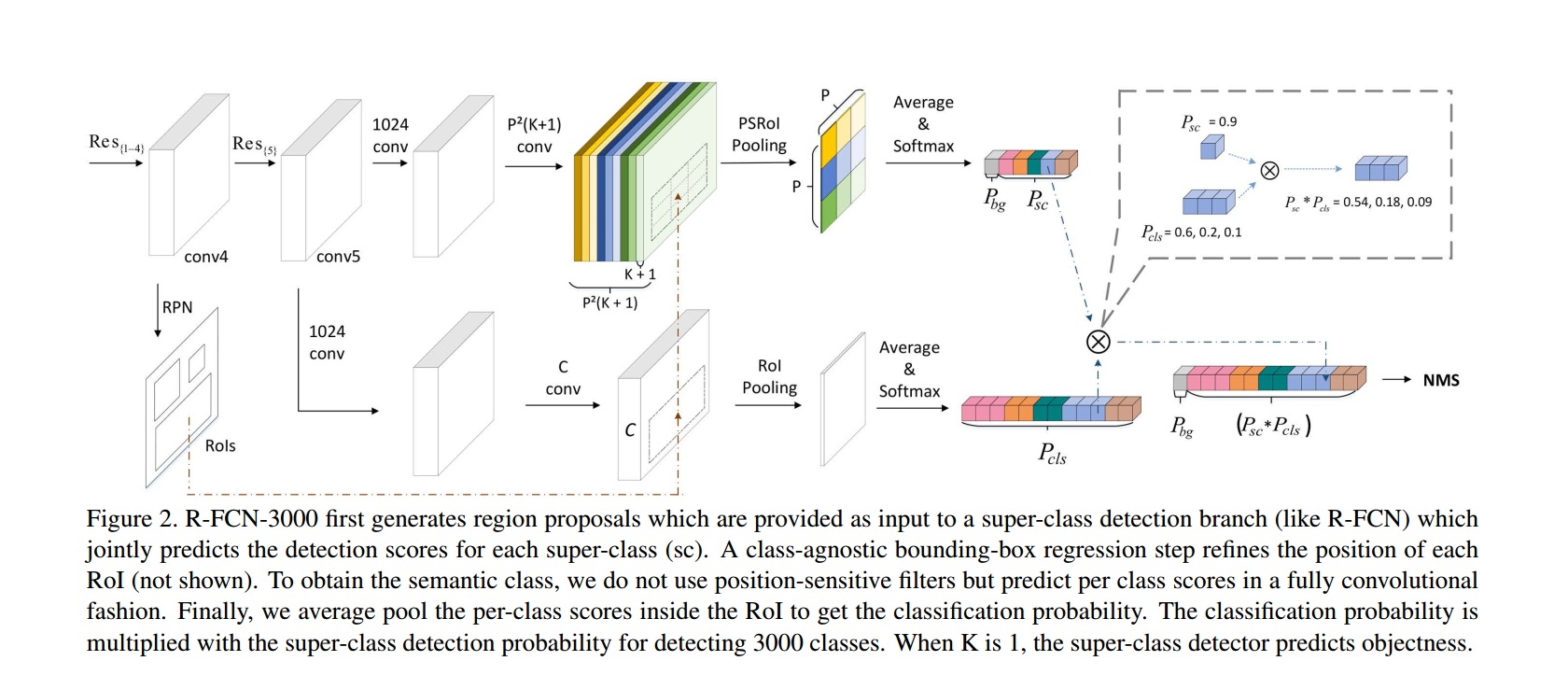
文章采用的就是先划分5个大类,然后再划分子类的方法。 $C$表示所有的类别数目。可以划分成$K$个super-class。。。
- 划分方法是:在resnet101的最后一层输出(2048维)的feature 向量求均值,再使用k-means聚类得到$K$个super-class。
- 标记方法:$ki$表示第$i$个super class,$cj$表示在第$k$个super class中的第$j$个子类。满足$ki={c1,c2,c3……,cj}$和$\sum^K_{i=1}|k_i|=C$的关系。
如图2所示:上面支路表示super class的分类,position sensitive层的卷积核数是$P^2(K+1)$。该条支路对super class做分类,数目固定,即便sub class增加,也不会影响这条支路的计算量。
下面那条支路是做精细化分类的,这条支路中有$C$个卷积核,表示所有的目标类别数。该条支路没有用位置敏感的卷积层来得到ps score map,是为了减少计算量。即便$C$从20增加到3000,该条支路的分类层卷积核数目只是从20变成了3000,相比较原本的R-FCN中$(C+1)\times P^2$来说,计算量是原本的$1/P^2$,所以计算量并不大。
两条支路输出的类别概率分别是$K+1$和$C$维的,将两条支路的前景ROI概率相乘便得到了最后$C$维的输出,即最终的概率。
损失函数:平衡多任务训练损失的重要性
训练检测器时,使用了OHEM和smooth L1的定位损失。
精细化分类支路,只对正样本($C$个目标类别)应用softmax损失函数,因为正样本的ROI与所有proposal数目相比很小,所以这条分支上的损失乘以权重0.05,这样他的梯度就不会主导网络的训练。(听起来怎么这么怪呢,我觉得不对啊,正样本数目少,损失占比小,前面的权重不是应该更大才对么。。。。。)。
3.实验:
当$K$为1时,上面支路的输出即为objectness的概率,即当前ROI是否包含目标。
1.super class数目影响

(a)和(b)是在给定总的类别数的前提下,super-class数量对实验结果的影响,当super-class数量为1的时候,就相当于用于object detection的那部分(Figure2中上面那条支路)是用来检测一个object是background还是foreground。可以看出实验效果基本上随着super-class数量的增加而提升。
(c)则是在给定super-class=1的前提下,总的类别数对最后实验结果的影响。
2.聚类数目与时间的对比

总的class数量为1000前提下,对不同的聚类数目与时间和效果的对比。
二、YOLO9000
1.YOLOv1
第一代的YOLO把检测问题建模成一个回归问题,直接使用一个单一的卷积网络对整张图像进行推理,预测边界框和类别概率。极大的降低了计算量,达到了实时的效果。
它将图像分成$S\times S$的网格,每个网格预测$B$(2)个bounding box和置信度和$C$个条件类别概率,置信度,条件类别概率分别定义为
$$
Pr(Object)IOU_{pred}^{truth}
$$
预测时候类别概率:
$$
Pr(Class_i|Object)Pr(Object)IOU_{pred}^{truth}=Pr(Class_i)IOU_{pred}^{truth}
$$
同时预测,最后在VOC数据集上,使用的$S=7,B=2,C=20$,最后的预测是一个$7\times7\times30$的张量。
在预测阶段,YOLO产生的proposal更少,只有98个,而RCNN有2000个。因此YOLO更快,且精度低,小目标检测很不准确。
2.YOLOv2
几点改进:
- 引入batch normalization,去掉v1中的dropout,正则化模型。 gain:2%
- 训练时使用更高分辨率的图像进行训练,(224->448),使网络能够适应更高分辨输入。gain:4%
- anchor box: box数目从98变成$13\times13\times9=1521$,召回率提升,准确率略微下降
- 使用k均值进行维度聚类,距离度量定义为IOU
- 使用sigmod函数对每个cell预测的$tx,ty$进行约束到0-1之间,提高模型训练稳定性。gain:5%
- 将大特征图$26\times26$下采样维度变高,和最后的$13\times13$的特征图拼接,获得精细化特征。gain:1%
- multi-scale training
- 提出了Darknet19……
3.YOLO9000
目前检测数据集因为标注成本,普遍数据量不是很大,而分类数据集的规模则很大。为了使得模型能够识别9000种的类别,作者将数据集进行了融合,提出了word tree的类别层次结构和联合训练方法。
detection的数据集类别较少,比较粗糙,而classification的数据集类别范围更宽。
以ImageNet为例:
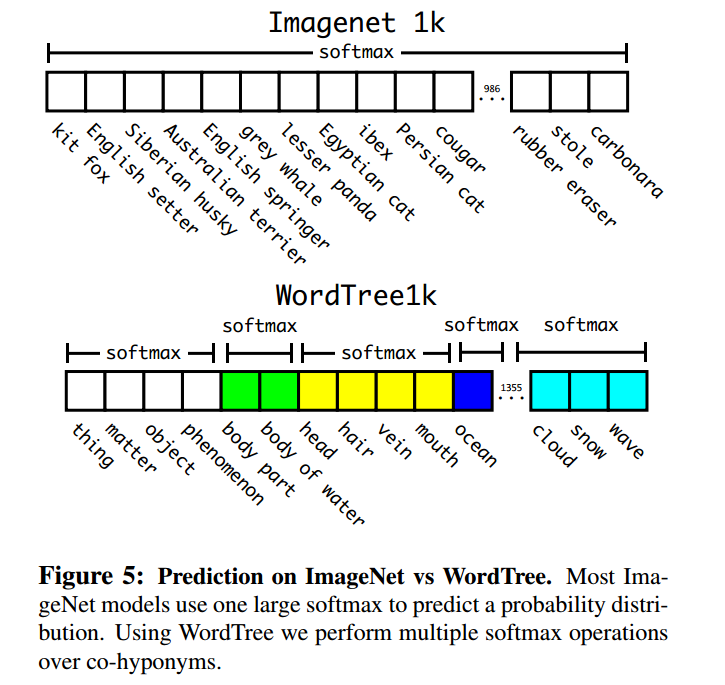
一般训练ImageNet时,都会使用一个1000类的softmax函数,而wordtree上,作者添加了396种新类,将类别做了划分。最后使用相同训练方法的效果,word tree仅下降了一点点,而且只是新类的影响.
作者最后使用COCO和ImageNet进行融合,如下图所示:
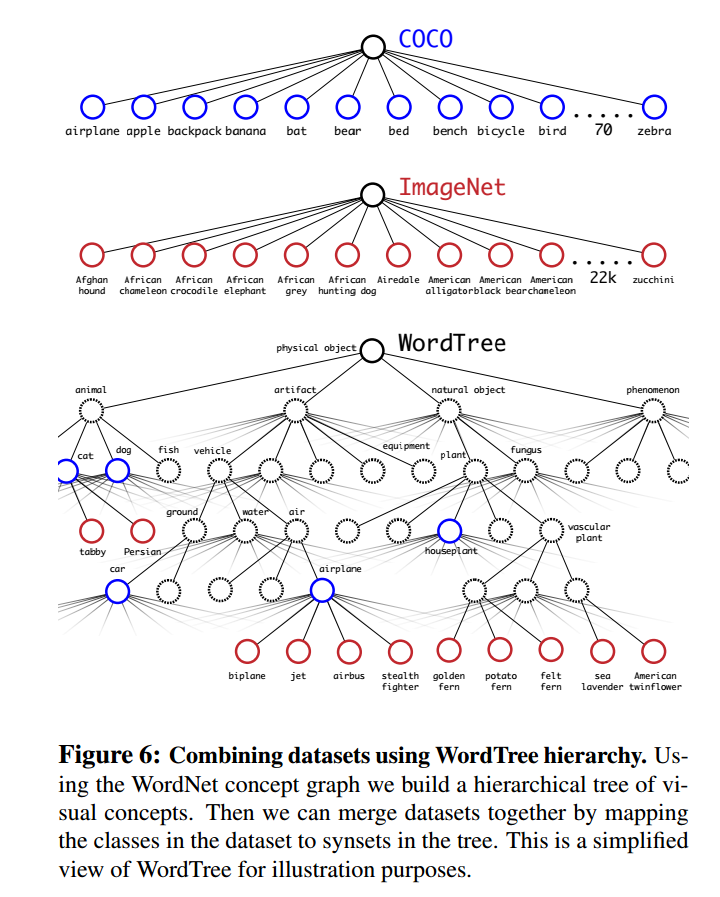
训练的方法是,当网络看见检测标记的图片时,则回传YOLOv2的损失,当看见分类图片时,只回传分类损失。最后使得网络能够识别宽范围的类别。
三、Google Open Image-Object Detection Track
谷歌的OpenImageDatasetV4一共有大约900万张图片,具有几千以上的image-level的标注。其中V4的训练集包含174万张图片,标注了14.6million的边界框,600个类,所以是现在最大的检测训练集。
比赛数据集划分: train (1,743,042), validation (41,620), and test (125,436) sets.
图片大小:长边 最多 1024 pixels on their longest side, while preserving their original aspect-ratio.
试验方案1:YOLOv3
这是最初采取的方案,训练了3天之后发现效果很差,出来的类别分数特别低。本来YOLO3框框是不太准,所以换了retinanet.
试验方案2:Retinanet
1.retinanet相关
两篇论文:
Feature Pyramid Networks for Object detection
各版本code:
博客:
The intuition behind RetinaNet写的非常好
2.实验细节
关于调参方案,参照了几个链接:
首先直接500类训练,使用的backbone是resnet50.由于训练集数目众多,为了能够尽快训练,所以没有使用更深的网络。
- 划分类别
比赛数据的类别层次结构参见这张图:hierarchy_visualizer
通过观察类别,发现其中person类和person相关的clothing类占了大约80类,因此,在训练整个数据集的同时,我又将这80类相关的图片挑了出来,只训练这80类。
- 输入大小
训练初期,将图片resize到$800\times600$,为了快速训练,尽管初期的训练不够准确,但是能让模型尽快见过尽量多的图片,从而加快训练过程。训练几个epoch之后,将图片分辨率提高到的大小在进行训练,让网络学习到更加精细化的特征。
还有一个减小训练时长的方法就是,去掉BN层中的weight decay.7 minute training of Imagenet on 2,048 GPUs
- 尽量使用大的batch-size训练
Multi-gpu
参照MegDet,如果使用小的batchsize来进行训练的话,可能存在:正负样本比例失调、BN层统计不准确,训练时间长、梯度不稳定等特点,因此要尽量使用大的batch-size进行训练。我使用的集群一个节点只有两张V100的GPU,且,一张有16G RAM,按理说,应该可以将batch-size设的大一点,但是总是报OOM的错误,我就只能最高设到4,即一张卡2张图片。
multi-machine
这个horvod居然是Uber的,咳咳咳,想不到啊。
参考论文:Horovod: fast and easy distributed deep learning in TensorFlow
3.参数:
| 1 | load_in_memory | 0 | |
|---|---|---|---|
| 3 | validation_sample_size | 10000 | |
| 4 | step per epoch | 10000 | |
| 5 | batch-size | 4 | |
| 2 | GPU | 2张v100 | |
| 6 | num_threads | 100 | |
| 9 | lr_factor | 0.3 | |
| 14 | pad_method | resize | |
| 15 | encoder_depth | 50 | |
| 16 | fixed_w | 512 | |
| 18 | fixed_h | 512 | |
| 19 | num_classes | 10 | |
| 24 | pi | 0.01 | |
| 28 | long_dim | 960 | |
| 30 | short_dim | 640 | |
| 33 | epochs_nr | 100 | |
| 35 | aspect_ratios | [1/2., 1/1., 2/1.] | |
| 36 | num_workers | 4 | |
| 37 | lr | 1e-05 | |
| 41 | image_channels | 3 | |
| 42 | scale_ratios | [1., pow(2,1/3.), pow(2,2/3.)] | |
| 45 | momentum | 0.9 | |
| 46 | loader_mode | resize | |
| 47 | batch_size_train | 4 | |
| 48 | batch_size_inference | 1 | |
| 50 | l2_reg_conv | 0.0001 | |
| 52 | classification_threshold | 0.5 | |
| 53 | nms_threshold | 0.5 |
4.retinanet的弊端
四、Facebook的Large minibatch SGD
论文:Accurate, Large Minibatch SGD
笔记:如何评价Facebook Training ImageNet in 1 Hour这篇论文?
1.