作者:konglanfang
主要是IOUnet介绍和几种roi pooling方式的讲解。
一、MegNet
Batchsize的问题
小batchsize问题
图像识别中,batchsize设置的很大 ,128,甚至上千的水平,使得人们可以在半小时或者一小时能完成ImageNet的训练。
而在COCO Detection问题中,batchsize普遍使用的很小,一般为2,8,最多也就16,这个结果和classification根本比不了。为什么物体检测的batchsize这么小?
因为对于图像识别任务:算法只需要判断一张图片中的主体,主要物体所占的像素比例通常较大,因此一张$224\times 224$的图片足矣。而目标检测任务中,往往需要检测一些小的物体,这些小物体在最后的特征图中所占像素的比例特别小,常常不足1%,而现在的神经网络一般会逐渐缩小特征图的尺寸,为了保证小物体在最后的特征图中占有一定比例,算法需要输入较大的图片,通常$800\times600$以上。
当输入图像的尺寸增长,其所占显存也增加,因此不能训练大batch-size的目标检测模型。而小的batch-size有下面几个几个问题:
- 梯度不稳定:因为batchsize小,每次迭代的生成的梯度变化会非常大,导致SGD算法在一个区域内来回震荡,不宜收敛到局部最优值。
- BN层统计不准确:batch-size较小难以满足BN层的统计需求。人们在训练的过程中,固定住BN层的参数,意味着BN层还保留着ImageNet数据集中的设置,但其余参数却是COCO数据集的拟合结果。这种模型内部参数的不匹配会影响最后的检测效果。
- 正负样本比例失调:mini-batch中图片变化可能非常大,有些正样本很少,导致其比例很少。当调大batchsize时,正样本比例会比之前要高一些。
- 训练时间长
MegDet改进
- brain++,大量底层支持,FPN
- 多卡BN,解决BN统计不准确的问题:单卡自主统计BN的参数,再将参数发送到单张卡上进行合并,最后再把BN的结果同步到其他卡上,以进行下一步的训练。
- Sublinear Memory技术
- 大batchsize下的调参技巧:16-batch的FPN的学习率为0.02,而MegDet的batchsize是256,则设定三个阶段:前两个阶段将学习率除以10,最后一个阶段学习率减半。
二、IOU-Net
1.定位置信度
现代CNN的目标检测器依赖于bbox回归和非极大值抑制来定位物体。具体到二阶段的检测器来说,主要包含三步:
- 区分前景和背景的proposal,并且分配类别标签。
- 通过最大化检测结果和ground truth之间的IOU来回归出一组系数,从而定位物体。
- 使用非极大值抑制来去除冗余的检测框。
但是我们只有反映分类置信度的类别分数,却没有定位置信度。
缺点:
- 执行非极大值抑制的过程并不能保证定位准确率,因为NMS的过程都是使用分类分数作为排序标准。比如:分类分数高的但是它和对应的groundtruth之间的IOU较小,导致IOU较高但是分类分数较低的box被抑制掉。
- 因为没有定位置信度的概念,我们在进行边界框回归的过程是一个非单调的过程,即box的定位准确度逐步退化。
见下图:

针对这两个问题,作者提出了IOU-net来在检测过程中预测IOU的分数:
- 使用IOU-guided NMS
- optimization-based的边界框修正过程
2.IOU-Net
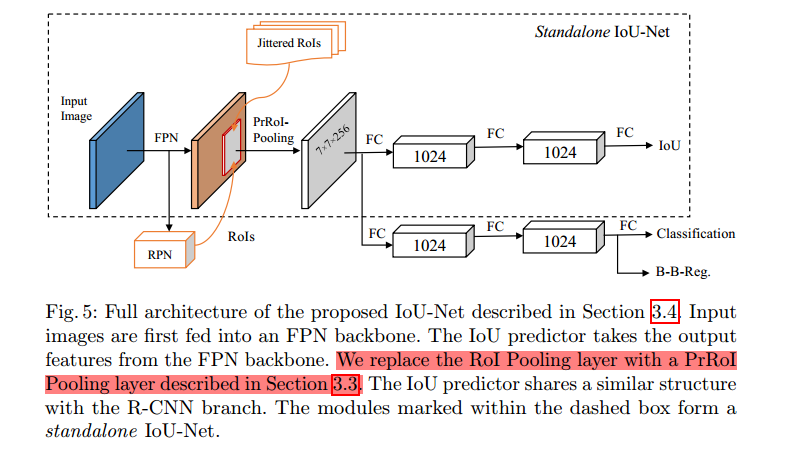
本文采用通用目标检测器FPN做实验,在其基础上又加了一路IOU分支。IOU预测器的输入是FPN输出的特征,然后估计每个边界框与ground truth的定位准确度,即IOU.
训练过程:
训练IOU-NET分支时,候选边界框不是从RPN中取出的proposal,而是由GTbox产生的。具体过程大概是:
- GTbox的产生:使用训练集中的GTbox,加上随机生成的参数,变成一堆候选边界框。
- 然后将IOU小于0.5的候选边界框删除。
- 我们均匀的从候选集合中采样训练数据。
- 候选框的特征是从Precise ROI Pooling层提取的。这些特征送入一个两层的前向网络来预测IOU分数。为了更好的性能,使用class-aware的IOUpredictor.
该IOU预测器可以兼容绝大部分基于ROI的目标检测器。
3.IOU-guided NMS
见本人的另一篇笔记:NMS专题
4.Non-monotonic bounding box regression
回归问题建模
一般的边界框回归问题可以写成下式:
$$
c^*=argmin_c crit(\textbf{transform}(box_{det},c),box_{gt})
$$
$c$是变换的参数,$crit$是两个边界框之间的距离标准:
- 在Fast R-CNN中,$crit$是$smoothL1$损失;
- 在Unit Box中,$crit$是$-\textbf{ln(IoU)}$.
regression-based方法
使用前向网络直接估计$c^{*}$的最优解。 但是回归过程定位准确性会退化,非单调。
optimization-based方法
IOU-Net直接预测$\textbf{IoU}(box_{det},box_{gt})$.因为precise roi pooling的缘故,可以直接计算IOU的边界框定点的梯度,然后利用梯度提升算法优化式子1找到其最优解。
算法如下:

下面具体介绍下precise roi pooling是怎么操作的:
5.改进的ROI Pooling
一张图概括ROI pooling,ROI align,和积分的ROI Pooling:roi pooling也就是扣取特征图的过程。最原始的RoI Pooling比较暴力,直接将roi边界拉到外层最靠近的整数边界;MaskRCNN中提出的ROI Align则是使用双线性插值,取周围四个格点计算采样点的像素值;而我们提出来的PrROI Pooling则是使用积分的过程来代替插值过程,这样可以更好的扣去特征图,且使得坐标点处可微。
注意:
下面三种都是使用平均池化方法。
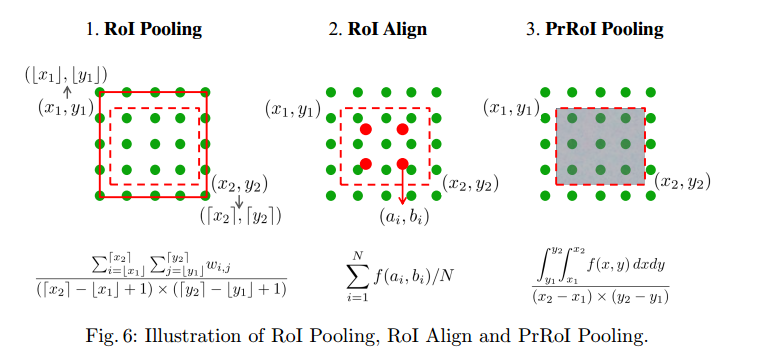
RoI Pooling
两次量化
- original box:[1.6,1.6,11,9.2]->feature map roi:[0.8,0.8,5.5,4.6]->round roi box:[1,1,6,5]四舍五入
- round roi box[1,1,6,5]->grid:[左上角坐标下取整,右上角坐标上取整]
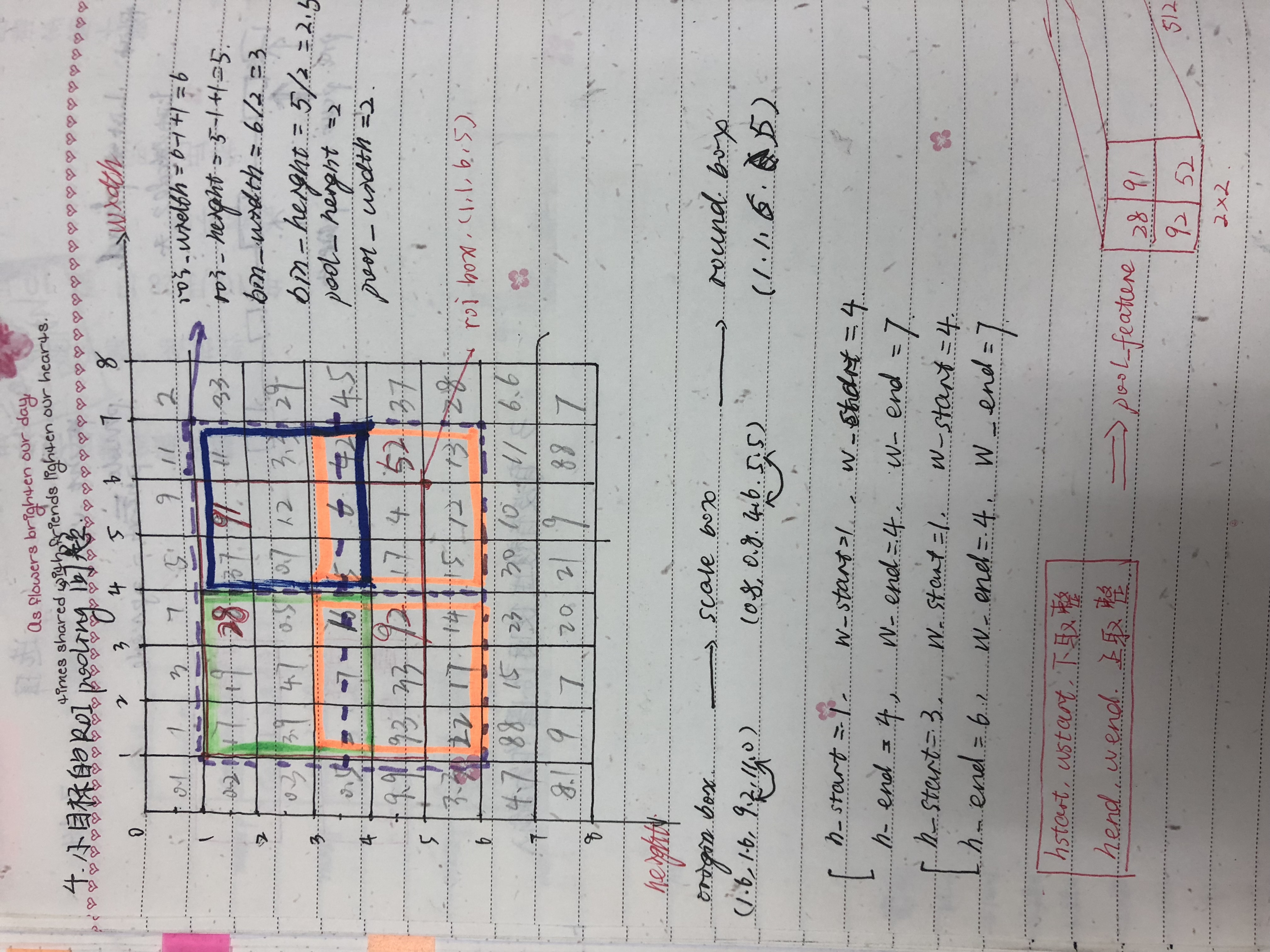
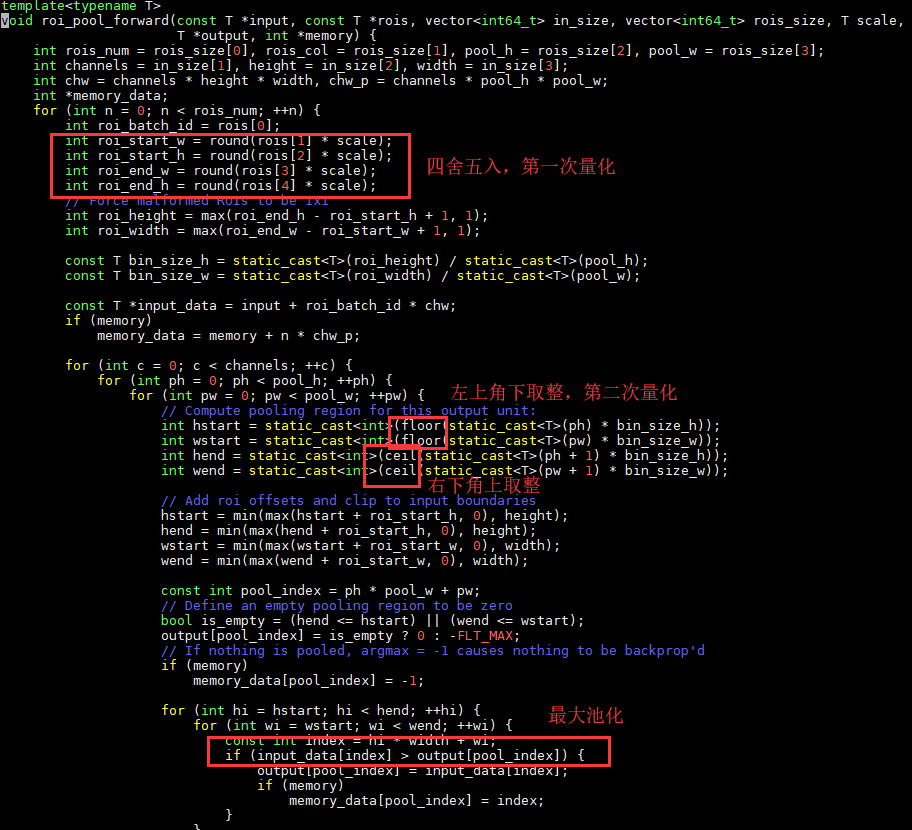
代码
反传
$$
\frac{\partial L}{\partial x_i}=\sum_r\sum_j[i=i*(r,j)]\frac{\partial L}{\partial y_{rj}}
$$
$x_i$代表池化前的特征图像素值,$y_{i,j}$代表池化后的第$r$个候选区域的第$j$个点,$i*(r,j)$代表点$y_{rj}$像素值的来源,即最大池化时选出来的最大像素值所在的点的坐标。即ROI Pooling只会将梯度回传至池化前特征图上贡献像素值的那个点,即$i=i*(r,j)$
RoI Align
过程
相比roi pooling,roi align取消了两次量化过程,使用双线性插值得到坐标点。
假设每个bin采样点是4个,则每个bin的值计算如图6-2所示,即平均池化。而每个采样点的值由双线性插值得到:
$$
f(x,y)=\sum_{i,j}IC(x,y,i,j)\times w_{i,j}
$$
其中,
$$
IC(x,y,i,j)=max(0,1-|x-i|)\times max(0,1-|y-j|)
$$
是每个点的插值系数。
这个插值系数怎么推的?
这部分可以具体去看:wiki双线性插值


上式中,$w1,w2,w3,w4$就是论文中的$IC(x,y,i,j)$, 四个格点的插值系数。
代码
反传
$$
\frac{\partial L}{\partial x_i}=\sum_r\sum_j[d(i,i*(r,j))<1](1-\Delta h)(i-\Delta w)\frac{\partial L}{\partial y_{rj}}
$$
其中,$d(.)$表示两点之间的距离,$\Delta h,\Delta w$表示$x_i$和$x_i*(r,j)$纵横坐标的差值,相乘得到双线性插值的系数,乘在原始梯度上。累加符号表示:池化前特征图上点$x_i$所贡献的所有的池化后的特征图上的点$y_{rj}$的梯度,都要累加起来,回传到点$x_i$.
由反传公式可知,ROI Align在坐标点处的梯度不是连续可微的。
Precise RoI Pooling
过程
我们将ROI的一个小bin表示为$(x_1,y_1)(x_2,y_2)$,表示左上和右下的连续坐标点。采样平均池化和二阶积分来计算其特征图:
$$
\textbf{PrPool}(bin,\textbf{F})=\frac{\int_{y_1}^{y_2}\int_{x_1}^{x_2} {f(x,y)} ,{\rm d}x{\rm d}y}{(x_2-x_1)\times(y_2-y_1)}
$$
与RoI Align(N是预先定义的,而不是关于bin大小自适应的)相反,提出的PrRoI池直接计算基于连续特征图的二阶积分。
反传
所以$\textbf{PrPool}(bin,\textbf{F})$是在各坐标点连续可微,举例:
$$
\frac{\partial \textbf{PrPool}(bin,\textbf{F})}{\partial x_1}=\frac{\textbf{PrPool}(bin,\textbf{F})}{x_2-x_1}-\frac{\int_{y_1}^{y_2}f(x_1,y)dy}{(x_2-x_1)\times(y_2-y_1)}
$$
代码
5.联合训练
采用FPN作为框架,CNN特征提取部分成为backbone,采用ResNet-FPN ,应用到每个roi上的模块称为head.
训练时,IOU Predictor和RCNN的分类与回归分支并行工作,输入的特征都是从backbone里面来的。
训练参数
- 使用预训练模型ResNet初始化权重,新加的层的权重以高斯分布(均值0,标准差0.01/0.001).
- IOU predictor采用smooth L1损失训练,训练数据是每个batch的图片上产生的。IOU的label归一化到【-1,1】之间。
- 输入图片:resize到长边最多1200,短边800.
- 分类和回归分支训练的时候,每张图片需要512个ROI(from RPN)
- batchsize=16,160k次迭代,学习率0.01,120k迭代后降为1/10.最开始训练的10k次迭代使用学习率0.004.weight decay为0.0001,动量0.9
前向过程
首先对初始坐标应用边界框回归。
为了加快推理速度,首先在所有检测到的边界框上应用 IoU-guided NMS
对分类置信度top 100的box进行基于优化的边界框修正。
修正参数为:步长$\lambda=0.5$,eraly-stop阈值$\Omega_1=0.001$,定位退化容忍度$\Omega_2=-0.01$,迭代次数$T=5$
6.结果
NMS对比
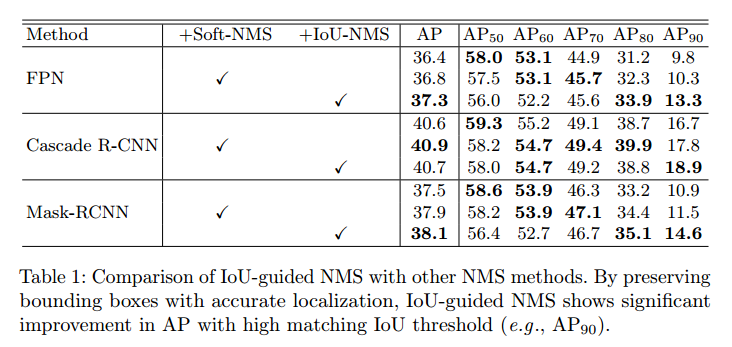
- Soft-NMS 能保留更多边界框(其中没有真正的「抑制」)
- IoU 引导式 NMS 还能通过改善检测到的边界框的定位来提升结果。因此,在高 IoU 指标(比如 $AP_{90}$)上,IoU 引导式 NMS 显著优于基准方法。
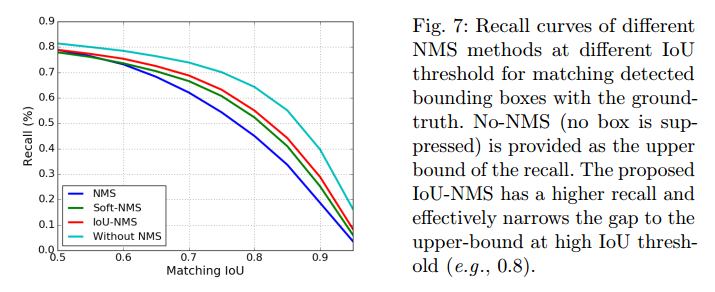
- 提供了 No-NMS(不抑制边界框)作为召回率曲线的上限
- IoU-NMS 有更高的召回率,并且在高 IoU 阈值(比如 0.8)下能有效收窄与上限的差距。
Refinement 对比
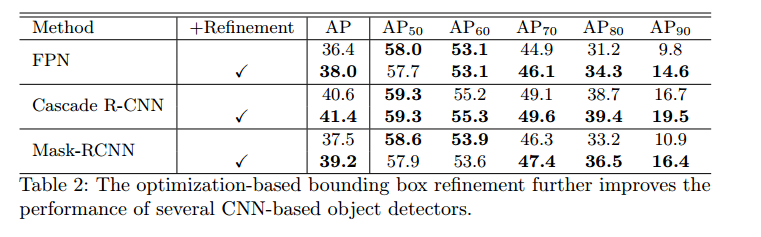
- 基于优化的边界框修正与大多数基于 CNN 的目标检测器 [16,3,10] 都兼容.
- 即使是对有三级边界框回归运算的 Cascade R-CNN,这种改进方法能进一步将 $AP_{90}$提升 2.8%,将整体 $AP$ 提升 0.8%。
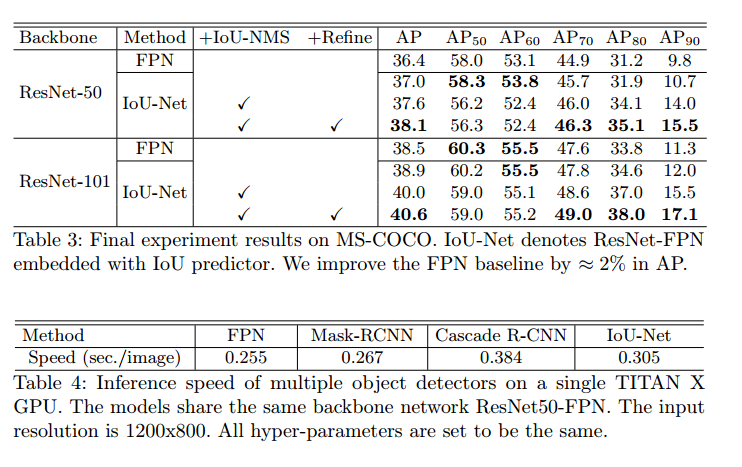
最终结果和速度对比
Reference
论文:MegDet: A Large Mini-Batch Object Detector
Acquisition of Localization Confidence for Accurate Object Detection