一篇将二阶段检测器分解开来,探究各部分参数对速度和精度的
摘要
本文目的是指导大家如何在选择检测框架时能够达到合适的精度和速度和内存使用率。
最近提出了很多十分成功的检测系统,但是直接比较他们显得很不合理,因为大家的基础特征提取网络(VGG,RESNET等)、默认的图像分辨率、不同的硬件和软件平台等都不一样。
我们使用一个统一的Faster R-CNN,SSD,RFCN的实验,来分解到每个单元,来查看这些各个部分对速度和精度的trade-off。
最后本文提出了,能够达到速度极致的、可以部署到手机上的检测器,和能够在coco数据集上达到最好效果的检测器。
引言
由于卷积神经网络的应用,目标检测近年来取得了巨大进展。一些现代的目标检测器诸如:faster rcnn、SSD、rfcn、yolo等可以部署到消费产品上(谷歌相册等),并能取得很好的效果,一些速度快的甚至能在移动设备上运行。
一般评价检测器性能,使用的指标是mean average precision(map),但是运行时间、内存占用等对于实时任务来说也很重要。比如:
- 移动设备:内存
- 自动驾驶:实时
- 服务器端:吞吐量,但是有更多空间来提高精度
那些在公开数据集上竞赛的,都用到了各种metrics,比如模型集成、随机裁剪等手段,很大限制了速度。
RFCN,SSD,YOLO等详细讨论过运行时间。但是只着重于能够达到多少帧率,并没有讨论速度和精度的accuracy。
尽管分类任务中经常讨论accuracy和speed的tradeoff,但是检测任务更加复杂。为了公平起见,本文讨论的前题是,没有模型集成、multicrop、水平翻转这些metric的single detector、singlepass的模型。且只关注test时间,而不是train时间。
总结下来:本文贡献就是:
- 实现了meta-architecture的 faster rcnn,SSD,yolo
- 发现faster rcnn使用更少的proposal能够大大加速,而精度不会掉很多。SSD对特征提取网络并不怎么敏感,相对于RFCN和faster rcnn。想要提高精度,只能牺牲速度。
meta-architecture
(这部分写的非常好,很好的概括了发展历史,我要拿去河边烤烤,嘻嘻嘻==)
神经网络在近年来成为了目标检测的主流方法。本章中,我们讨论几个亮点文章。RCNN: 是第一个基于卷积网络的目标检测框架。被图像分类的成功所激发,RCNN直接在输入图像上crop出proposal,然后送入到神经网络分类器。这种方法很费时费内存,因为需要很多的crop来保证不丢失目标,导致重叠的crops之间的大量重复计算。Fast R-CNN: 将输入图片只进行一次特征提取,因此crop之间可以共享特征提取。
Faster R-CNN: 上面两种方法必须依赖外部的proposal生成器。何凯明引入不同空间位置、scale、aspect ratio的anchor(或者priors,default box),来收集proposal。
…………………………一堆介绍anchor的。重点是:anchor的好处:对box的预测量可以写成图像上的tiled predictors,这样就能共享参数了!!!(The advantage of having a regular grid of anchors is that predictions for these boxes can be written as tiled predictors on the image with shared parameters (i.e., convolutions) )
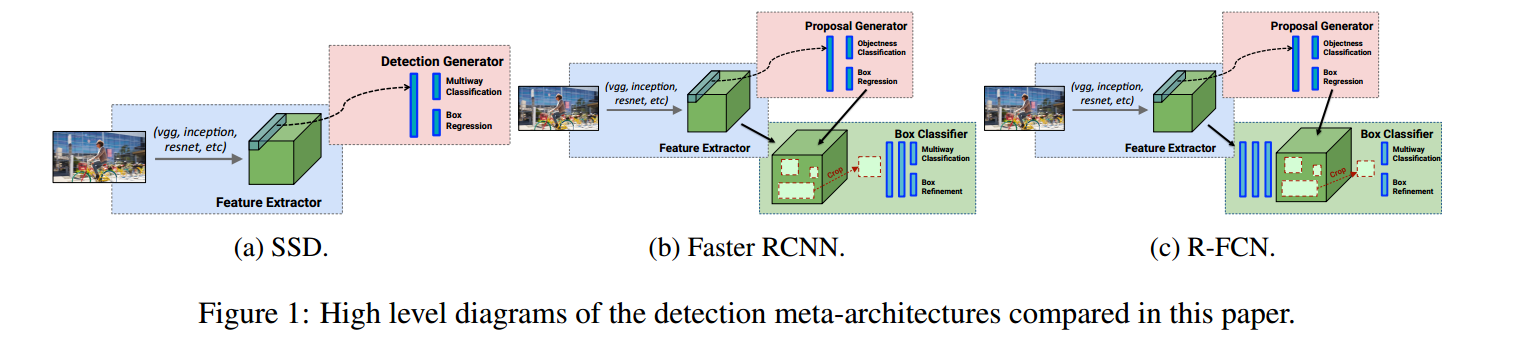

- [ ] Single Shot Detector (SSD)
- [ ] Faster R-CNN :Notably, one does not crop proposals directly from the image and re-run crops through
the feature extractor, which would be duplicated computation. However there is part of the computation that must be run once per region, and thus the running time depends on the number of regions proposed by the RPN.
- [ ] R-FCN
experiment setup
不同的算法难以比较:深度学习平台的不同(caffe,torch,等),不同的硬件,有些工作针对精度优化,有些是针对速度进行优化,训练的设置也会不同(training 集,training+validation集)
本文建立了一个可以自由切换特征提取器、损失函数的框架。