NMS(Non-Maximum Suppression)在计算机视觉任务中有着广泛应用,如目标检测、边缘检测等。
本文重点介绍目标检测中的NMS及其改进,以及边缘检测、角点检测中的非极大值抑制。
一、NMS in Object Detection
首先可以看下cousera上吴恩达关于NMS的讲解视频.

非极大值抑制,就是局部最大搜索。例如在人脸检测中,滑动窗口经过特征提取,分类器分类识别后,每个窗口都会得到一个分数,但是会有很多重叠交叉的边界框,因此需要NMS来选取这些邻域内分数最大的,并抑制那些分数低的窗口。我们的目的就是去除冗余的检测框,保留最好的那个。如上图所示。
1.单类别
对于Bounding Box的列表B及其对应的置信度S,采用下面的计算方式.选择具有最大score的检测框M,将其从B集合中移除并加入到最终的检测结果D中.通常将B中剩余检测框中与M的IoU大于阈值Nt的框从B中移除.重复这个过程,直到B为空.
假设有6个矩形框,根据分类器的类别分类概率做排序,假设从小到大属于车辆的概率 分别为A、B、C、D、E、F。
- 从最大概率的框F开始,分别判断A,B,C,D,E与F的重叠率IOU是否大于阈值
- 假设B,D与F的IOU大于阈值,则去除B,D;并标记F是我们在第一轮中保留下来的
- 从剩下的A,C,E中,找到概率最大的E,判断A,C与E的IOU是否大于阈值。大于则扔掉,否则保留。并标记E是我们第二轮留下来的矩形框。
- 重复进行直到找到所有保留的框框。
代码:
1 | def py_cpu_nms(dets, thresh): |
2.多类别
多类别的就是在单类别上多加一层for循环,对每类进行NMS而已。
代码:
1 | if class_specific_filter: |
3.NMS损失
如果对每个类别进行NMS,会出现一种情况:当检测结果中包含两个被分配到不同类别的bbox且他们的IOU较大时,结果将不可接受。

《Rotated Region Based CNN for Ship Detection》中,引入了NMS损失,添加在训练的多任务损失中。
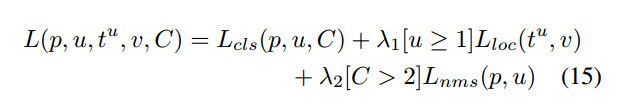
NMS损失和分类损失的定义相同。
$$
Lnms=Lcls(p,u)=-logp_u
$$
即为真实类别u对应的log损失,p是C个类别的预测概率。NMS损失实际是增加分类损失。
4.Soft-NMS
论文:Improving Object Detection With One Line of Code .
project:soft-nms-caffe
1.Hard NMS
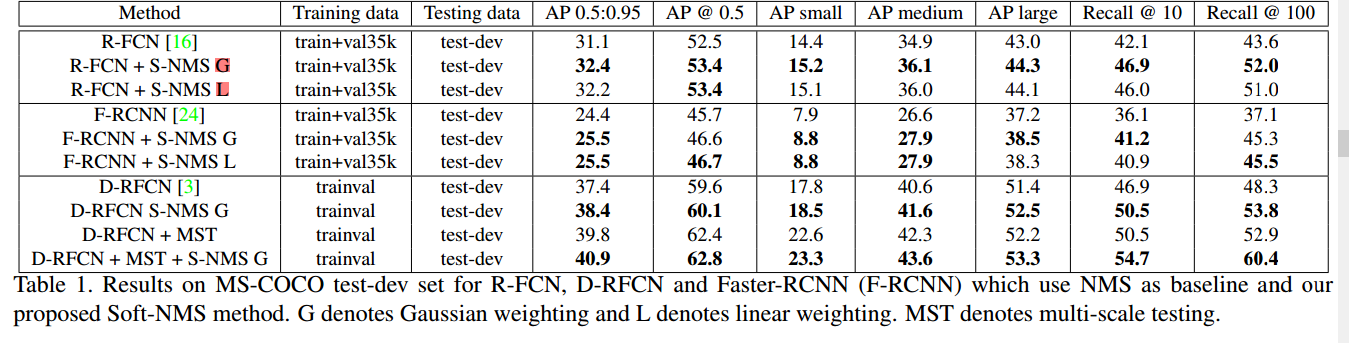
也就是传统的NMS,有一个问题,就是当两个gt的确存在目标,且重叠度很高时(大于NMS的阈值),NMS会将置信度较低的框去掉(score置为0),导致这个object丢失,最后ap下降。如下图所示:

选取NMS的阈值也有两个问题:
设$Ot$表示我们在检测评估时,设的将一个proposal划分为正样本的阈值(与gt的重叠率阈值):
threshold $Nt$很低时,周围的box都会被抑制掉,导致错误率上升
$Nt$很高时,导致$Ot$比较小的一些框框被保留下来,导致准确率的下降,false positive上升,true positive下降。
2. Soft NMS
思想:如果一个Bbox与M(置信度最高的框)的重叠率很大,应该赋予它一个很低的分数,而不是直接将score置为0;如果重叠度很低,那么就保留他原来的分数。见下图:

这里文章中提出了两种关于$s_if(iou(M,bi))$的式子:
linear function:
$$
s_i=\begin{cases}s_i,\quad iou(M,bi)<N_t \s_i(1-iou(M,bi)),\quad iou(M,bi)\ge N_t\end{cases}
$$
该线性函数不是连续的。我们希望:惩罚函数最好是连续的。当没有重叠时,既没有惩罚;当有很高的IOU时,惩罚因子也高。当IOU很低时,惩罚应该逐渐提高。因此,提出下面的函数:Gaussian Function:
$$
s_i=s_i e^{-\frac{iou(M,b_i)^2}{\sigma}},\quad \forall b_i\notin D
$$
时间复杂度分析:
对于每个detection box,需要计算的是$O(N)$,
对于$N$个detection box,需要计算$O(N^2)$.
因此时间复杂度和原本的相比没什么区别。
结果
在基于proposal方法的模型结果上应用比较好,检测效果提升:
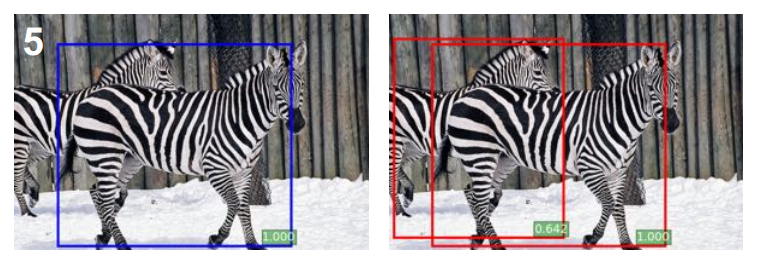
在R-FCN以及Faster-RCNN基于proposal的模型中的测试阶段运用Soft-NMS,在MS-COCO数据集上mAP@[0.5:0.95]能够获得大约1%的提升。因为他们的recall更高,在$Ot$更高的情况下有更高的提升空间。如果图片中出现羊群,鸟群,斑马群这样的易重叠的图片,map能提高的更多:3-6%。
但是对于SSD,YOLO这样不是基于proposal的检测器来说,几乎没有提升。
代码
参见caffe-c++代码:soft-nms
1 | def cpu_soft_nms(np.ndarray[float, ndim=2] boxes, float sigma=0.5, float Nt=0.3, float threshold=0.001, unsigned int method=0): |
二、IOU-guided NMS
在传统NMS中使用分类置信度作为排名标准,会导致分类和定位之间不匹配的问题,即IOU大、分类置信度较低的box被抑制掉。如下图所示;

尽管很多关于NMS改进算法提出了,比如soft-nms,2,但是都是基于参数的(parameter-based),因此计算过程需要更多的计算资源。
作者统计了IOU和分类置信度和定位置信度之间的皮尔森系数,发现定位置信度与分类置信度之间的相关性并不强.见下图:
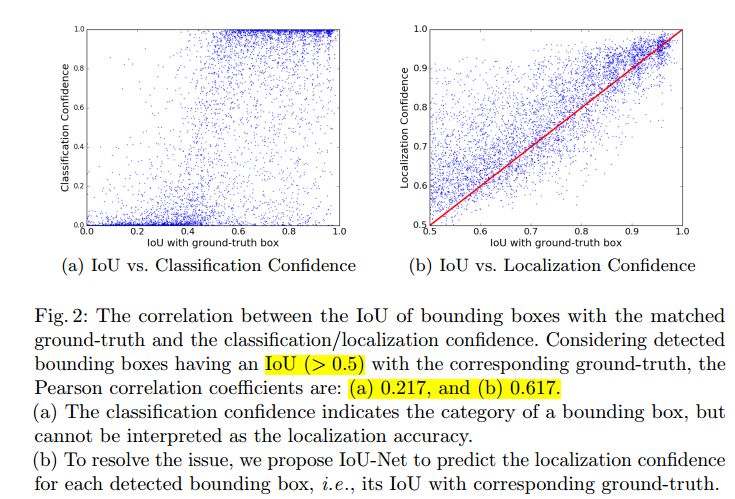
本文提出的IOU-net能够在前向过程中,直接预测proposal的IOU分数,然后利用和GT的IOU最高的box来抑制与他IOU超过阈值的其他的box,同时更新他的分类置信度。具体算法如下:

更多内容详见原论文:Acquisition of Localization Confidence for Accurate Object Detection
三、NMS in Canny
John Canny提出的Canny算子的论文中,非最大值抑制就只是在0、90、45、135四个梯度方向上进行的,每个像素点梯度方向按照相近程度用这四个方向来代替。这种情况下,非最大值抑制所比较的相邻两个像素就是:
1) 0:左边 和 右边
2)45:右上 和 左下
3)90: 上边 和 下边
4)135: 左上 和 右下
四、NMS in Harris
在3×3或5×5的邻域内进行非最大值抑制,局部最大值点即为图像中的角点。
Refenece
-